


大家好,我是二哥呀。
一开始,我在做 PaiAgent 这个 Vibe Coding 项目时,确实是在工作流跑完的时候一次性返回结果的,Vibe Coding 尽量小版本持续迭代。但这样的话,用户就无法感知工作流的实时执行状态。如果工作流非常复杂,需要等待的时间很久,用户很容易在等的过程中失去耐心。
所以在做 PaiFlow 的时候,我就决定,每一个节点的状态都应该实时推送给前端。有了这个前提,我们再来聊,消息是怎么回传的,实时通信又是怎么做的。
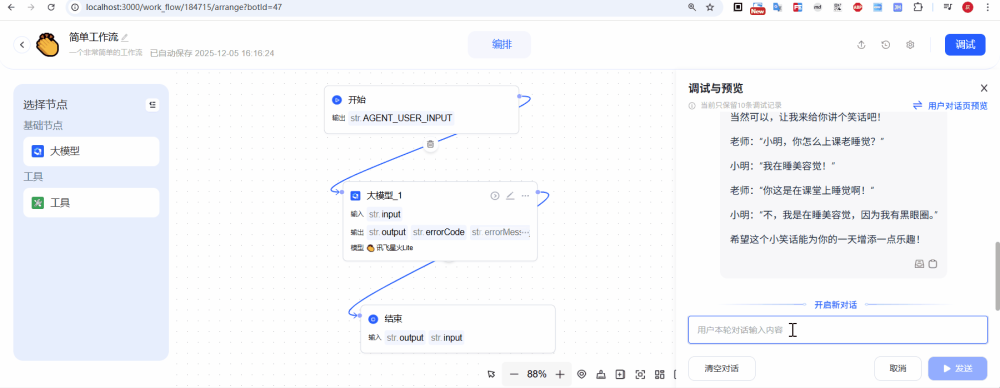
第一个是事件驱动。工作流的执行本质上是一连串状态的变化过程,节点开始、节点跑完、节点失败。所以我们要在每一个关键时刻,主动把事件抛出来,通过发布-订阅的方式,让前端感知到。
第二个是消息必须标准化,不能今天是这个状态,明天又多一个状态,所有回传消息都必须是统一的结构,不管是工作流级别的事件,还是节点级别的事件,前端只需要按照同一种方式去解析和渲染就好了。
第三个,在技术选型上,我们决定使用 Server-Sent Events,也就是 SSE。这种方式非常适合单向的,服务端向前端推送状态的场景;另外就是,派聪明 RAG 我们用了 WebSocket,之前也有球友说为什么不用 SSE,那这次我们就狠狠听劝,用。
前端发起工作流执行请求,后端一边跑 Workflow,一边把节点状态和 LLM 的流式输出持续推送给前端。这个业务并不复杂,但会涉及到非常多的组件。
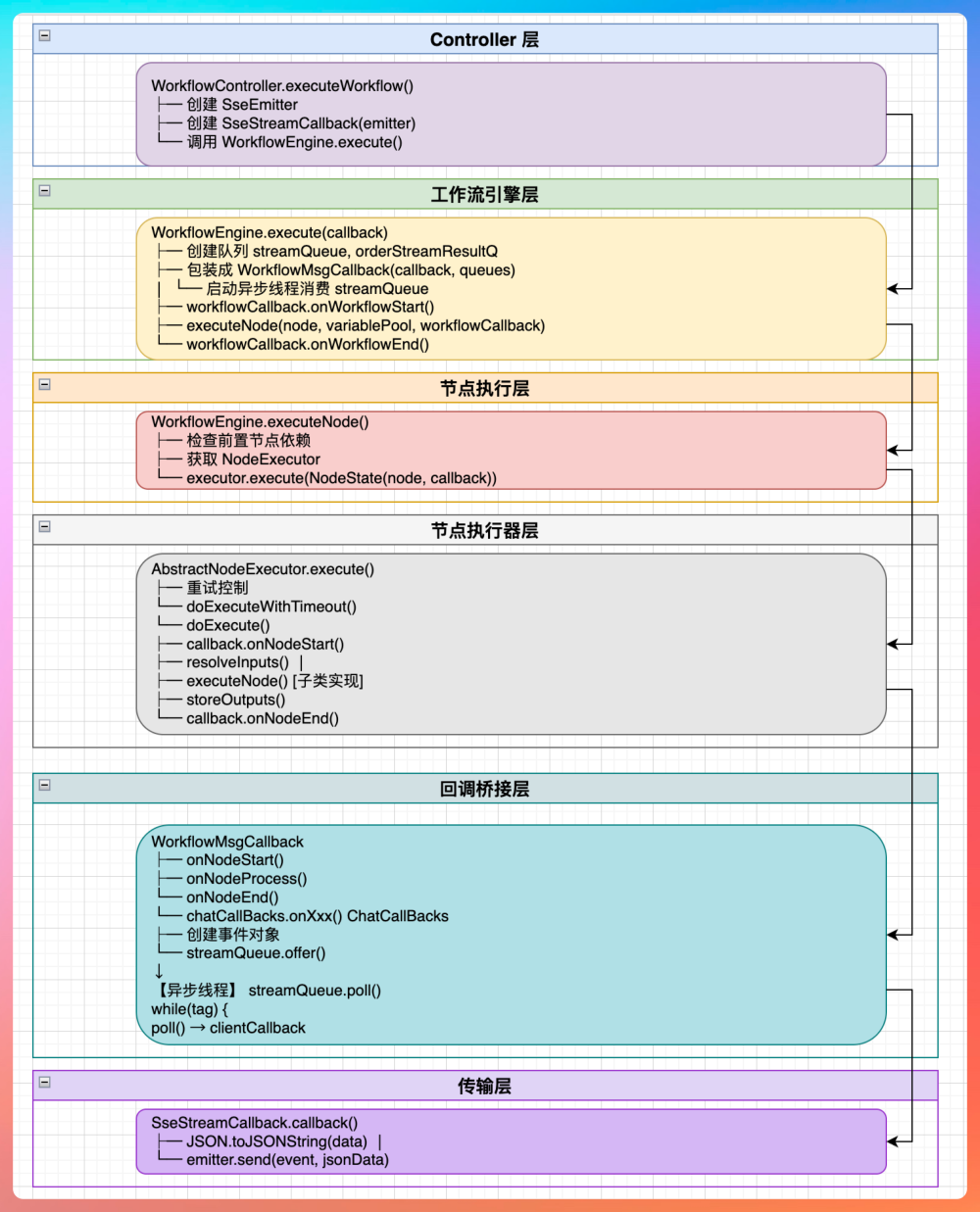
我们从入口开始看,WorkflowController.executeWorkflow 会先创建一个 SseEmitter 对象,然后将其作为参数创建 SseStreamCa...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

9人已点赞
热门评论
34 条评论
回复