


LLM节点执行器:PaiFlow核心设计,支持多模型流式输出
在 PaiFlow 里,LLM 节点是最核心的节点之一,它要做提示词拼装、多轮对话、流式输出、异常兜底。所以我们在实现上,力求:
第一,不管是 DeepSeek、讯飞星火、智谱,还是后面可能接入的其他模型,节点层都不应该感知这些差异。第二,它要理解“上下文”。提示词模板、变量替换、多轮对话历史,都要能兼顾。第三,支持实时反馈,流式输出几乎是刚需。
1.LLM节点执行器的整体设计
LLMNodeExecutor 是 PaiFlow 工作流引擎中专门负责与大语言模型(LLM)进行交互的节点执行器 。它的核心目标是:将工作流中的业务数据(如用户输入、上下文历史)转换为标准的 LLM 请求,然后处理 LLM 返回的响应(包括流式和非流式),并将输出格式化为工作流可以继续处理的结果。
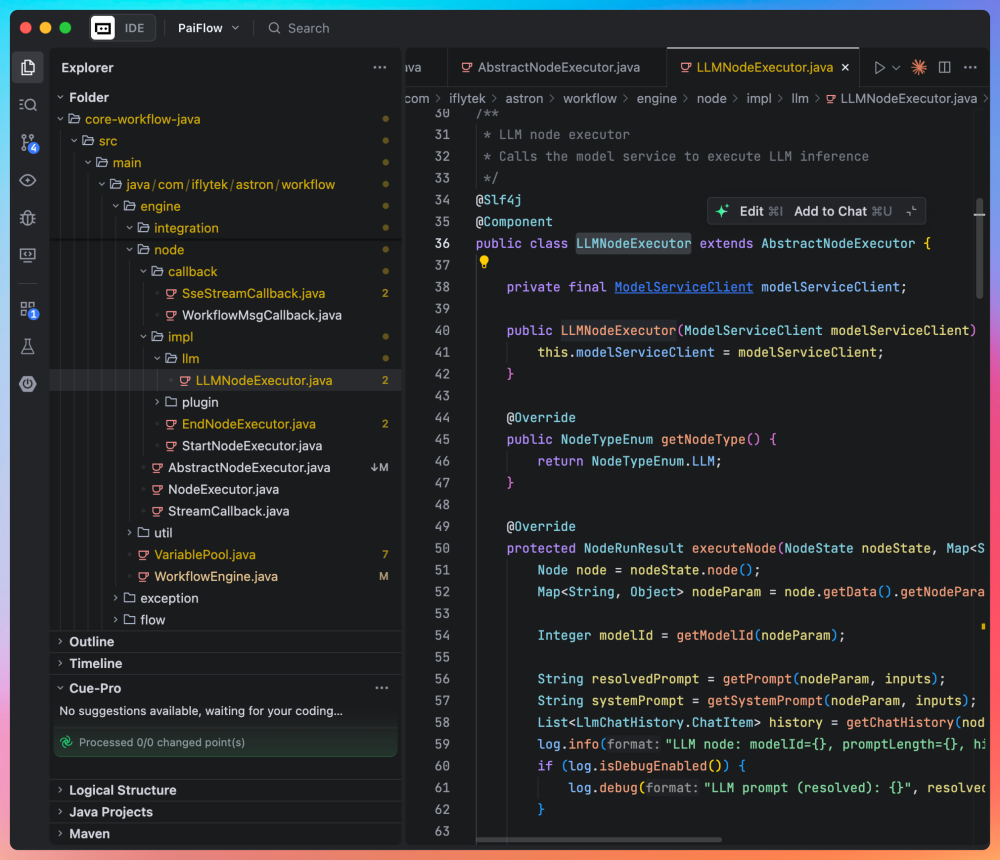
作为 AbstractNodeExecutor 的子类,它天然继承了超时、重试、输入解析、输出存储、事件回调( onNodeStart / onNodeEnd )等通用能力。
LLMNodeExecutor 的核心是实现 executeNode(...) 方法,在这个方法中注入 LLM 独有的业务逻辑。
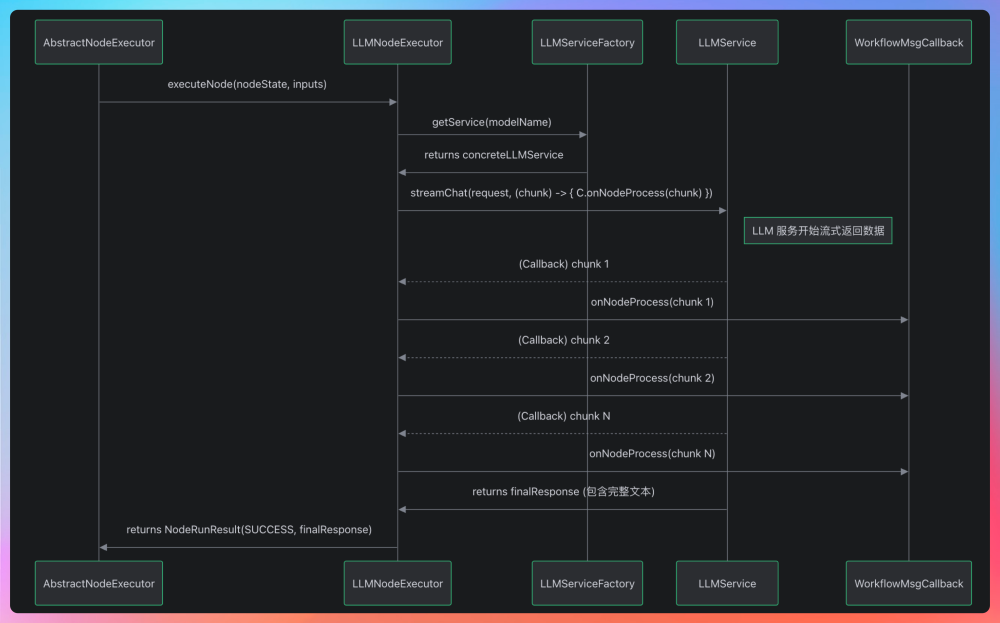
它通过经典的设计模式(模板方法模式+工厂模式),将通用流程控制、具体业务实现和底层服务依赖三者完美解耦。对上,遵守 AbstractNodeExecutor 定义的模板,无缝融入工作流的生命周期管理;对下 ,通过工厂和接口,灵活适配多种 LLM 服务。另外,还能通过 Callback 将引擎的 SSE 事件推送机制连接起来。
2.LLM节点执行器的具体实现
2.1 LLM节点的配置示例
LLM 节点的配置整体可以分为五个部分,第一部分是模型的选择,我们可以提前配置 DeepSeek、智谱、OpenAI、Claude、MiniMax 等等。
配置好后,可以在这里灵活切换。

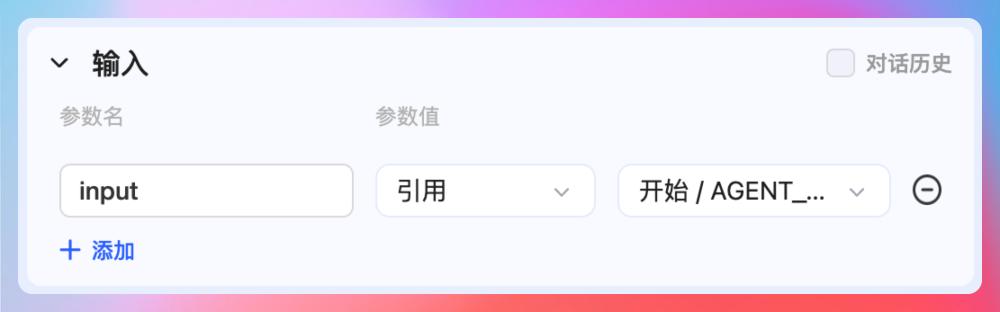
第二部分是输入,这部分可以动态添加参数,包括输入的固定值,引用前面节点的输出,还可以勾选对话历史。
第三部分是提示词,包括系统提示词和用户提示词。这里还可以通过 {{}}引用输入中配置的输入项,好原封不动的作为提示词的一部分发给大模型。

第四部分是输出配置,格式可以选 text 和 json,参数类型就比较多了,字符串,列表、数组都可以。
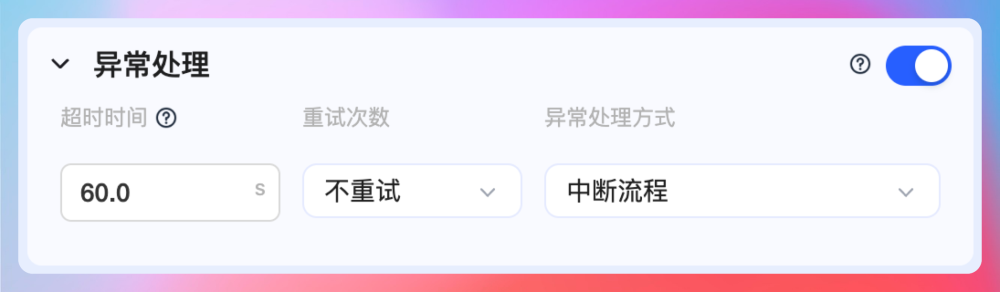
第五部分是异常处理,这里可以配置超时时间、重试次数、异常处理的方式等。
当发起流程执行的时候,这些配置信息会作为 JSON 格式传递给后端,大家看一眼参数名和参数值,基本上是能够知道每个参数是干嘛用的。
{
"data": {
"inputs": [
{
"fileType": "",
"id": "211eda5c-d627-4055-8b04-7f04caa52abc",
"name": "input",
"schema": {
"type": "string",
"value": {
"content": {
"id": "3c63b9b8-749f-4d2a-ba39-3711a59ec780",
"nodeId": "spark-llm::52dfad37-d36a-42d5-84a2-1f4e78309947",
"name": "output"
},
"type": "ref"
}
}
}
],
"nodeMeta": {
"nodeType": "基础节点",
"aliasName": "大模型_2"
},
"nodeParam": {
"maxTokens": 2048,
"topK": 4,
"auditing": "default",
"template": "{{input}}",
"respFormat": 0,
"appId": "appid",
"uid": "admin",
"enableChatHistoryV2": {
"isEnabled": true,
"rounds": 3
},
"templateErrMsg": "",
"llmId": 454665064,
"domain": "glm-4.5-flash",
"serviceId": "glm-4.5-flash",
"url": "https://open.bigmodel.cn/api/paas/v4/chat/completions",
"modelId": 3,
"isThink": false,
"multiMode": false,
"modelName": "智谱",
"modelEnabled": true,
"llmIdErrMsg": "",
"source": "openai",
"extraParams": {
"temperature": 1
},
"systemTemplate": "你现在是一个哲学大师,擅长从一段文本中提炼一段哲学意味的语句",
"setAnswerContentErrMsg": "",
"exceptionHandlingEdge": "fail_one_of::d169e701-cdae-4ce6-a724-27edfdb4f524",
"handlingEdge": "normal_one_of::56ced558-c343-49b4-a94e-67a7847f4f82",
"apiKey": "beb8fadc85(脱敏....)nbdFN8mqp",
"apiSecret": ""
},
"outputs": [
{
"id": "c2099874-060c-4f55-9033-53ca15ddecec",
"name": "output",
"schema": {
"description": "",
"type": "string"
}
}
],
"retryConfig": {
"shouldRetry": true,
"errorStrategy": 1,
"maxRetries": 1,
"timeout": 5,
"customOutput": {
"output": "错误了,这是预设的内容"
}
}
},
"id": "spark-llm::176fa697-0e10-49e7-be6a-c51bb485a205"
}
data 包含了 inputs、outputs、retryConfig、nodeMeta、nodeParam 等等,也就是前面提到的五个部分的配置。
inputs 描述了这个节点从上游节点接收到了什么数据。其中input 的类型是 ref,表明引用的是前一个节点的 output。
nodeMeta 主要是节点的元信息,比如节点类型和展示用的别名。
真正和 LLM 行为强相关的,是 nodeParam 这一块,也就是模型的提示词部分,其中 template 是用户提示词,systemTemplate 是系统级提示词;enableChatHistoryV2 用来控制是否开启多轮对话。
modelId、serviceId、domain、url、source 这一组字段,描述的是模型本身的信息,以及通过哪种方式去调用它。这个是通过前面的模型配置拉取过来的信息。
maxTokens、topK、extraParams 这些参数用来控制模型行为,比如生成长度、随机性等。
outputs 用来定义这个节点会向下游输出什么数据。一般定义为字符串类型的 output 就好了。
retryCo...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

5人已点赞
热门评论
16 条评论
回复