


✅派聪明 RAG知识库检索模块设计方案
知识库检索模块是派聪明这个 RAG 项目的核心功能模块,我们是基于 Elasticsearch 实现的文档混合检索能力,将语义检索和关键词检索结果结合起来,为用户提供更高质量的搜索体验。
该模块依赖于文件上传与解析模块完成的向量化处理,直接使用存储在 Elasticsearch 中的向量数据进行检索。系统目前使用豆包 API 生成文本向量,并将向量存储在 Elasticsearch 中。
模块整体分为两大块:
①、知识库检索
- 混合检索:结合语义检索和关键词检索结果,按权重排序返回搜索结果
- 支持指定返回结果数量:通过 topK 参数控制结果数量
②、权限控制
基于组织标签的数据权限:确保用户只能访问有权限的文档
支持层级权限验证:父标签权限自动包含所有子标签文档的访问权限
默认标签全局可访问:DEFAULT 标签资源对所有用户kaifang
用到的技术栈包括:
| 功能模块 | 技术选型 | 备注 |
|---|---|---|
| 全文检索 | Elasticsearch | 第一阶段,使用IK分词器 |
| 向量检索 | Elasticsearch | 第一阶段,使用dense_vector类型 |
| 向量检索 | FAISS | 第二阶段,提供更高性能的向量检索 |
| 缓存 | Redis | 缓存热点查询结果 |
| 数据库 | MySQL | 存储元数据 |
| 对象存储 | MinIO | 存储文档文件 |
整体的流程是这样的:
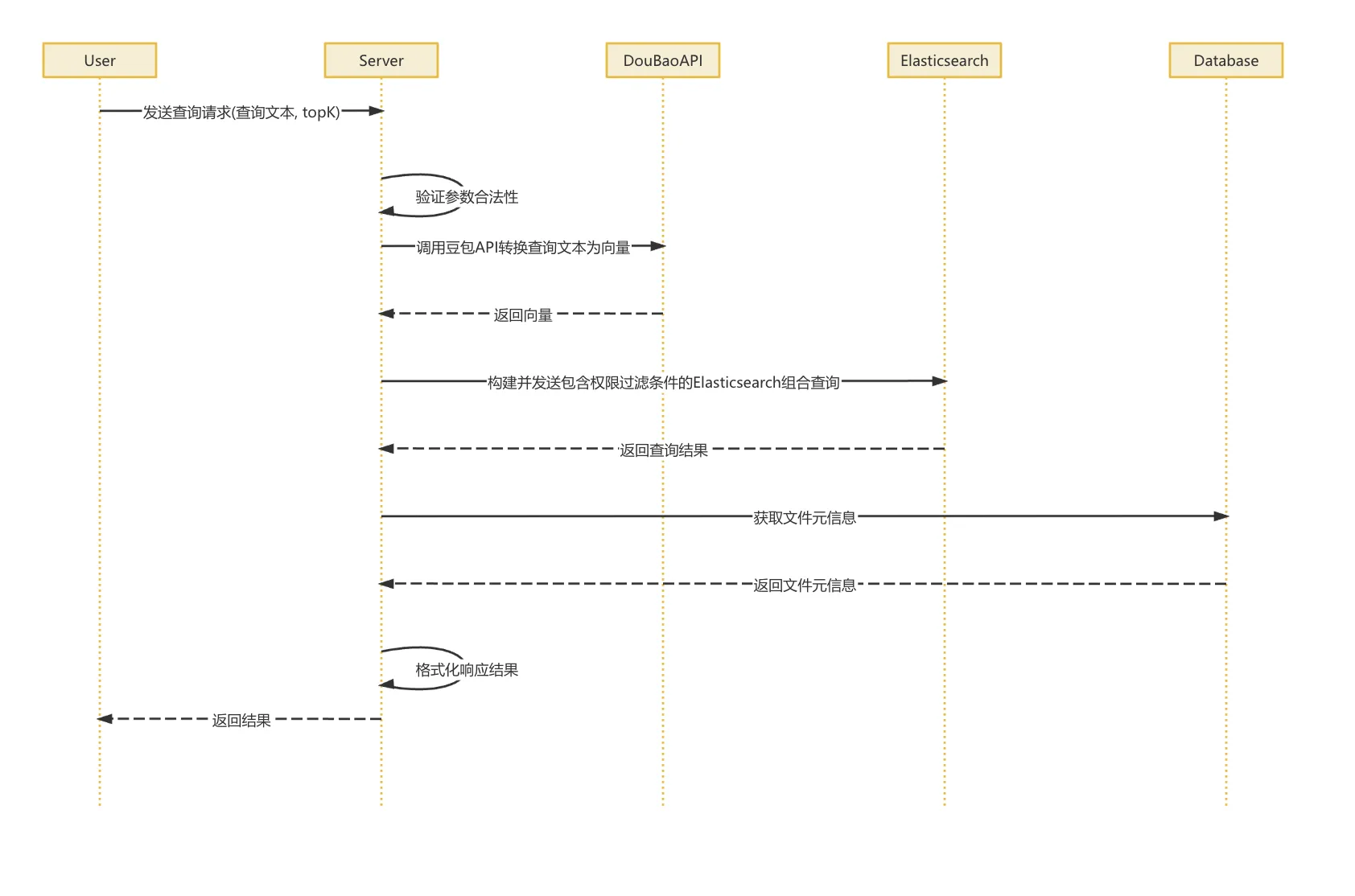
当用户发起一个查询请求时,...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

39人已点赞
热门评论
31 条评论
回复