


✅派聪明 RAG 系统用户管理面试题预测
1.我们来聊聊你项目中的用户管理模块。你能先整体介绍一下这个模块都实现了哪些核心功能吗?它的主要设计目标是什么?
派聪明的用户管理模块,主要围绕身份认证、权限控制和数据隔离三个目标来展开。
首先是用户注册与登录。用户通过用户名和密码完成登录认证,成功后系统会下发 JWT 作为用户的访问凭证,实现后续接口的身份校验。
其次是基于角色的权限管理。派聪明设计了 ADMIN 和 USER 两种角色。管理员拥有管理知识库、查看用户列表等最高权限,而普通用户只能查看自己私有的知识库和公开的知识库。
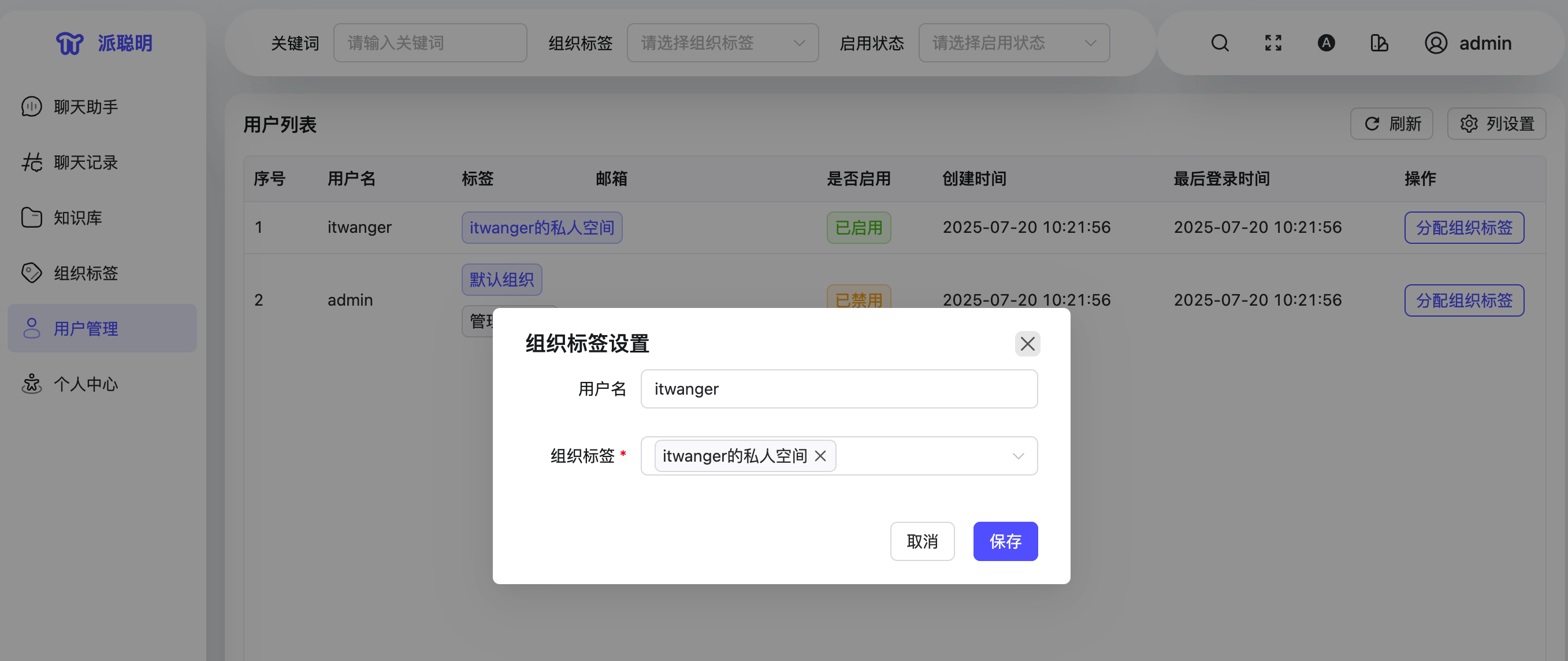
更有特色的是派聪明设计了一套“组织标签”机制。除了角色控制外,系统还允许为每个用户设置一个或多个“组织标签”,并支持设置“主组织”,用于实现多租户数据隔离——例如在文档上传或知识检索过程中,派聪明会基于用户的组织标签对数据进行过滤,确保用户只能访问自己组织内部的资源。
整体来说,用户管理模块不仅实现了基本的注册登录功能,还通过 RBAC 定义了用户“能做什么” ,还通过 组织标签定义了用户“能看什么”。
2.你提到了‘角色’和‘组织标签’,听起来这是一个很有意思的权限设计。为什么在有了传统的用户/管理员角色之后,还要引入‘组织标签’这个概念?它解决了什么具体问题?
为了解决 RBAC 的两个局限:权限控制粒度不够细和没办法基于数据属性做动态授权。
RBAC 解决的是“谁能做什么”的问题,通过为用户赋予角色,来限定功能权限。但在多部门、多租户的企业应用中,这种模式很容易遇到角色baozha的问题。比如,公司不同部门之间希望数据互相隔离,传统做法是为每个部门定义角色,但这会导致角色数量迅速膨胀。同时,RBAC 无法基于具体的文档属性去动态判断某条数据是否对某个用户可见。
组织标签机制,本质上是一种 ABAC 的简化实现。在用户层面,为每个用户打上组织标签(如部门),在文档层面,为每份文档标记上传者所属的组织标签。当用户访问知识库时,系统能够动态地基于“当前用户的组织标签”与“文档的组织标签”进行匹配过滤,从而实现更细粒度的数据隔离与动态授权。

这种“角色 + 标签”的混合机制,让派聪明既保留了 RBAC 模型的简单直观,又通过组织标签实现了多租户、多部门场景下的权限支持。例如,研发部的用户可以看到“研发部”标签下的所有文档,而无法访问市场部的知识库;同时,某些标记为“公开”的文档,任何用户都可以跨部门访问。
3.了解了。那在技术实现上,用户登录成功后,你是如何维持他的登录状态的?是用的传统Session,还是像JWT这样的Token方案?为什么做这个选择?
在派聪明项目中,我们采用了JWT 的方案,而不是传统的 Session 认证机制。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

57人已点赞
热门评论
100 条评论
回复