


美团大模型应用开发面经,主要是RAG这块
继续给大家分享美团大模型应用开发的面经,及详细答案,系好安全带,我们粗粗粗发~~
content
01、Embedding 向量检索的原理是什么?如何保证检索准确性?
“先说说你们项目里 Embedding 向量检索是怎么做的?”老王扶了扶快从鼻梁上掉下来的眼镜,开始拷打我派聪明 RAG 项目了。
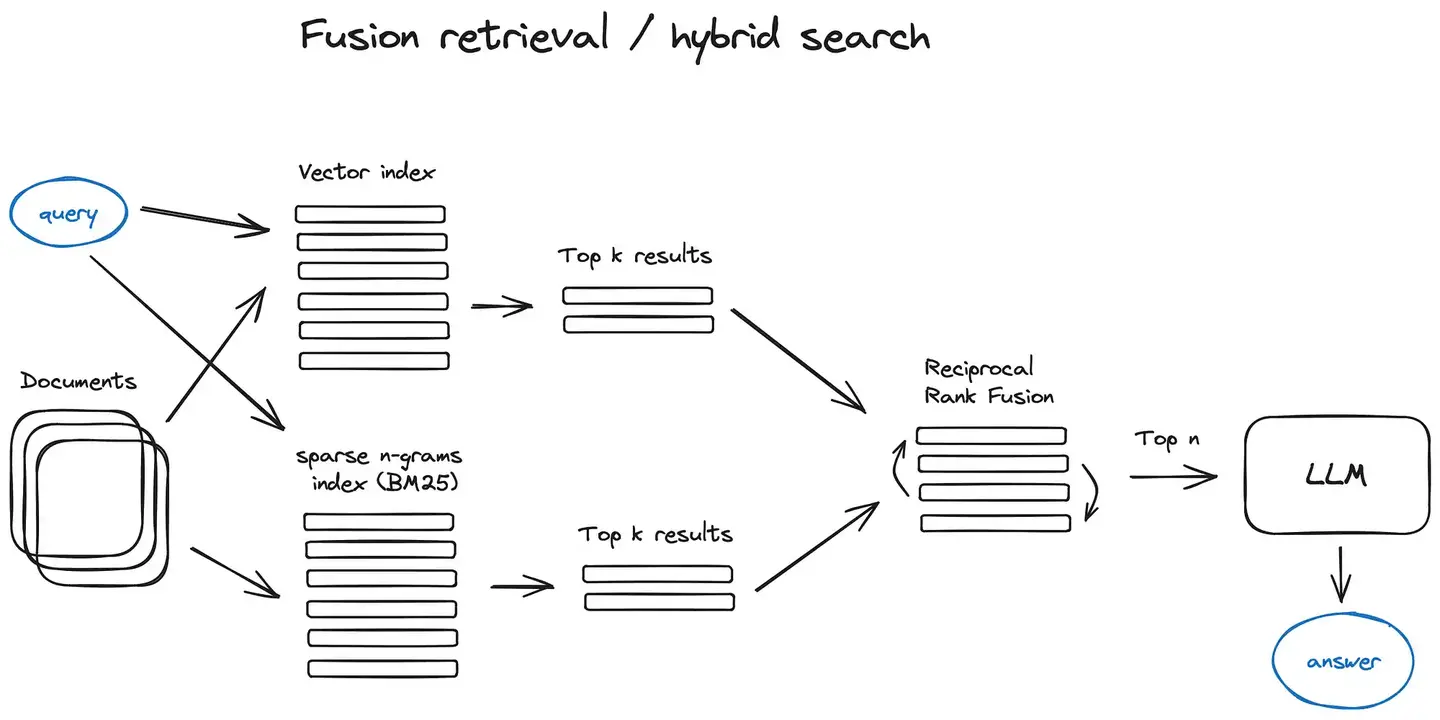
我说:“我们用的是阿里的 text-embedding-v4 模型,把文本转成 2048 维的向量,存到 Elasticsearch 里。检索的时候,用户的问题也会先过一遍 Embedding 模型,变成同维度的向量,然后用 ES 的 KNN 做近邻搜索。”
向量检索的原理是什么?
Embedding 模型干的事情,就是把一段文字映射到一个高维空间的点上。语义相近的文本,在这个空间里距离就近。比如“Java 的垃圾回收机制”和“JVM GC 原理”,虽然字面完全不一样,但 Embedding 之后的向量距离会非常近。
检索的时候就是在这个高维空间里找“最近的邻居”——K-Nearest Neighbors,简称 KNN。ES 8.x 原生就支持这个能力,不需要装额外的插件。
“那光靠向量检索能保证准确吗?”老王追问。
我说:“光靠向量检索肯定不够,所以我们做了混合检索。”
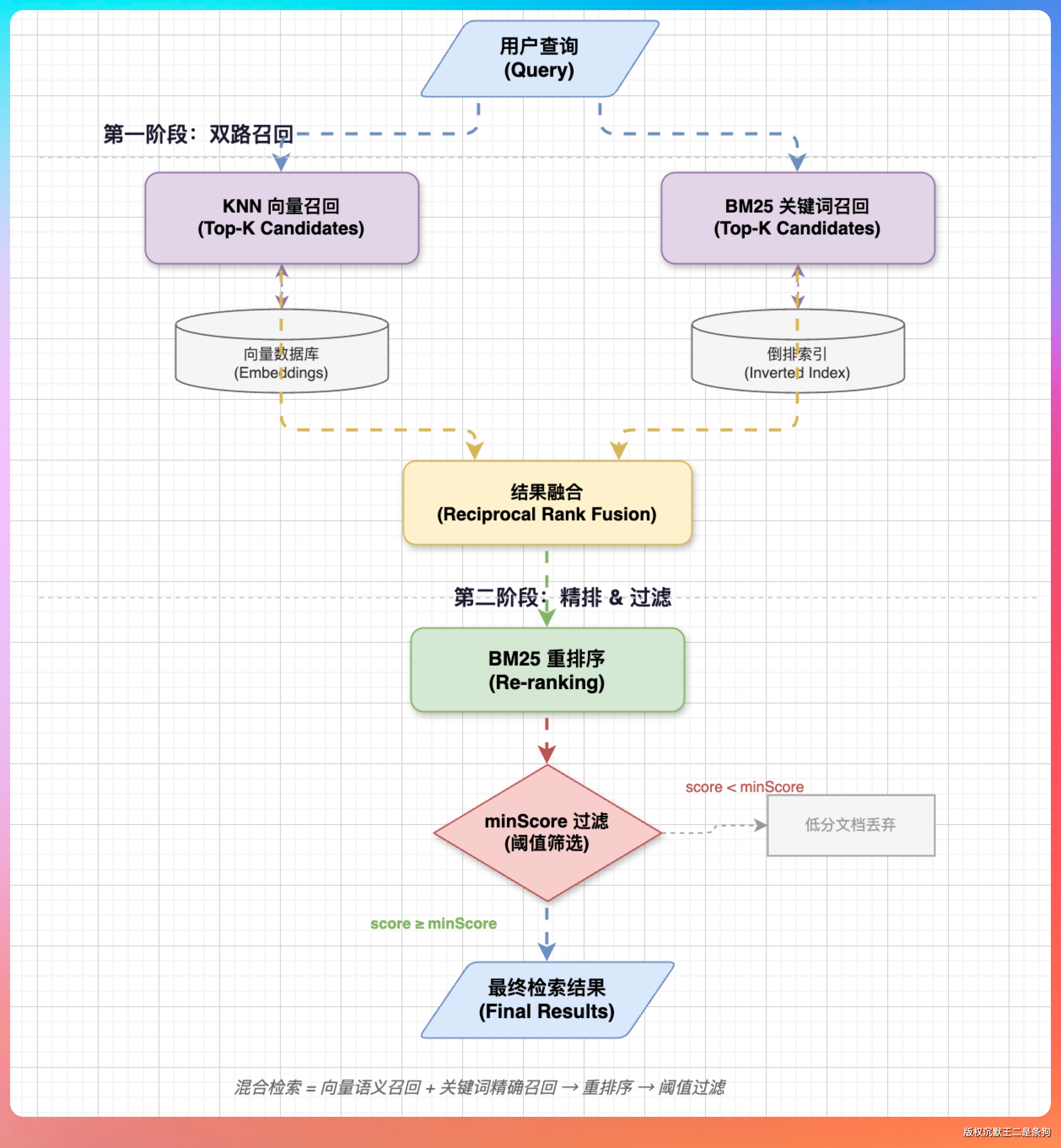
在 HybridSearchService 里,我们设计了一个两阶段检索策略:
第一阶段:KNN 向量召回 + 关键词必中。 先用 KNN 做大范围召回,召回窗口是 topK 的 30 倍。同时加一个 must match 条件,要求文档必须包含用户查询的关键词。这一步是“宁可多召,不能漏掉”。
// 第一阶段:KNN 向量召回
s.knn(kn -> kn
.field("vector")
.queryVector(queryVector)
.k(recallK) // recallK = topK * 30
.numCandidates(recallK)
);
// 关键词必中
s.query(q -> q.bool(b -> b
.must(mst -> mst.match(m -> m
.field("textContent").query(query)
))
));
第二阶段:BM25 重排序。 召回的结果用 BM25 算法重新打分。KNN 得分权重只占 0.2,BM25 占 1.0。因为纯向量检索有时候会把语义相关但答非所问的内容排前面,BM25 能把关键词匹配度高的内容拉上来。
// BM25 重排序
s.rescore(r -> r
.windowSize(recallK)
.query(rq -> rq
.queryWeight(0.2d) // KNN 得分权重 20%
.rescoreQueryWeight(1.0d) // BM25 权重 100%
.query(rqq -> rqq.match(m -> m
.field("textContent")
.query(query)
.operator(Operator.And)
))
)
);
另外还有一道保险——minScore(0.3d),低于 0.3 分的结果直接过滤掉,避免把完全不相关的内容推给用户。
老王听完点了点头:“不错,两阶段检索这个思路是对的。那你们的 Embedding 模型是怎么调用的?有没有做批量处理?”
我说:“有。EmbeddingClient 里做了分批处理,默认每批 100 条文本。因为 Dashscope 的 API 对单次请求有条数限制,所以大文件切片后不能一股脑全扔过去。而且加了重试策略,fixedDelay 重试 3 次,每次间隔 1 秒,超时时间设置为 30 秒:
public List embed(List texts, String requesterId, UsageType usageType) {
for (int start = 0; start < texts.size(); start += batchSize) {
List batch = texts.subList(start, end);
String response = callApiOnce(batch);
// 重试策略:固定间隔 1 秒,最多 3 次
.retryWhen(Retry.fixedDelay(3, Duration.ofSeconds(1)))
.block(Duration.ofSeconds(30));
}
return vectors;
}
还有一个容灾逻辑,如果向量生成失败了,检索会降级成纯文本检索。
02、Function Calling 如何解析用户的意图?
老王切到了新的话题:“Function Calling 了解吗?讲讲它是怎么解析用户意图的。”
我说:“那必须了解啊,这玩意儿现在几乎是 Agent 的标配。”
Function Calling 的核心思路其实也简单。
给大模型一份“工具清单”,每个工具有名字、描述、参数的 JSON Schema。用户说一句话,模型看看手里有哪些工具可用,判断这句话的意图是不是需要调某个工具,如果是,就返回一个结构化的函数调用请求。
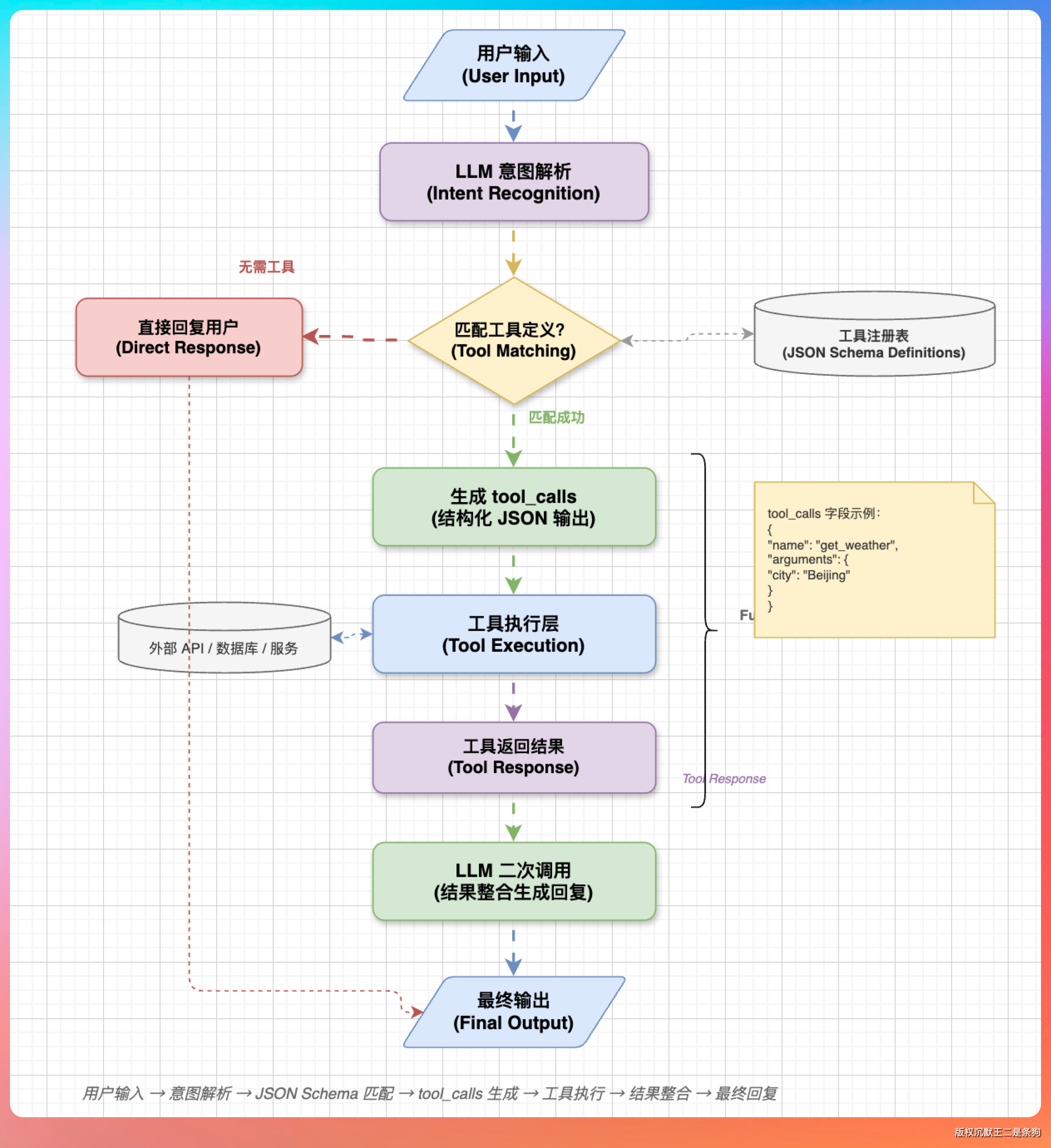
举个例子,用户说“帮我查一下北京明天的天气”,模型手里有个 get_we...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

4人已点赞
热门评论
7 条评论
回复