


RAG 项目派聪明的学习路线(怎么快速上手 Java+Go 版)
我这里再强调一下,一旦入门,就不要再长时间去通过视频学项目,否则你会发现自己工程能力提升很慢。养成看文档,看源码,看注释就能上手,对参加工作后快速融入到团队中,帮助会非常大。
很多球友像我反馈,看视频看完啥也记不住,就是因为视频不太适合你深入去学习一个项目,因为你的注意力无法把项目的源码、教程、面试题结合起来。

那这篇就给大家讲一下派聪明的学习方案。

第一步,先当用户,把项目跑起来
这是最最重要,也是最有成就感的一步。在分析任何代码之前,你必须让它在你的电脑上成为一个活生生的应用。
仔细阅读前置环境搭建的教程https://paicoding.com/column/10/4
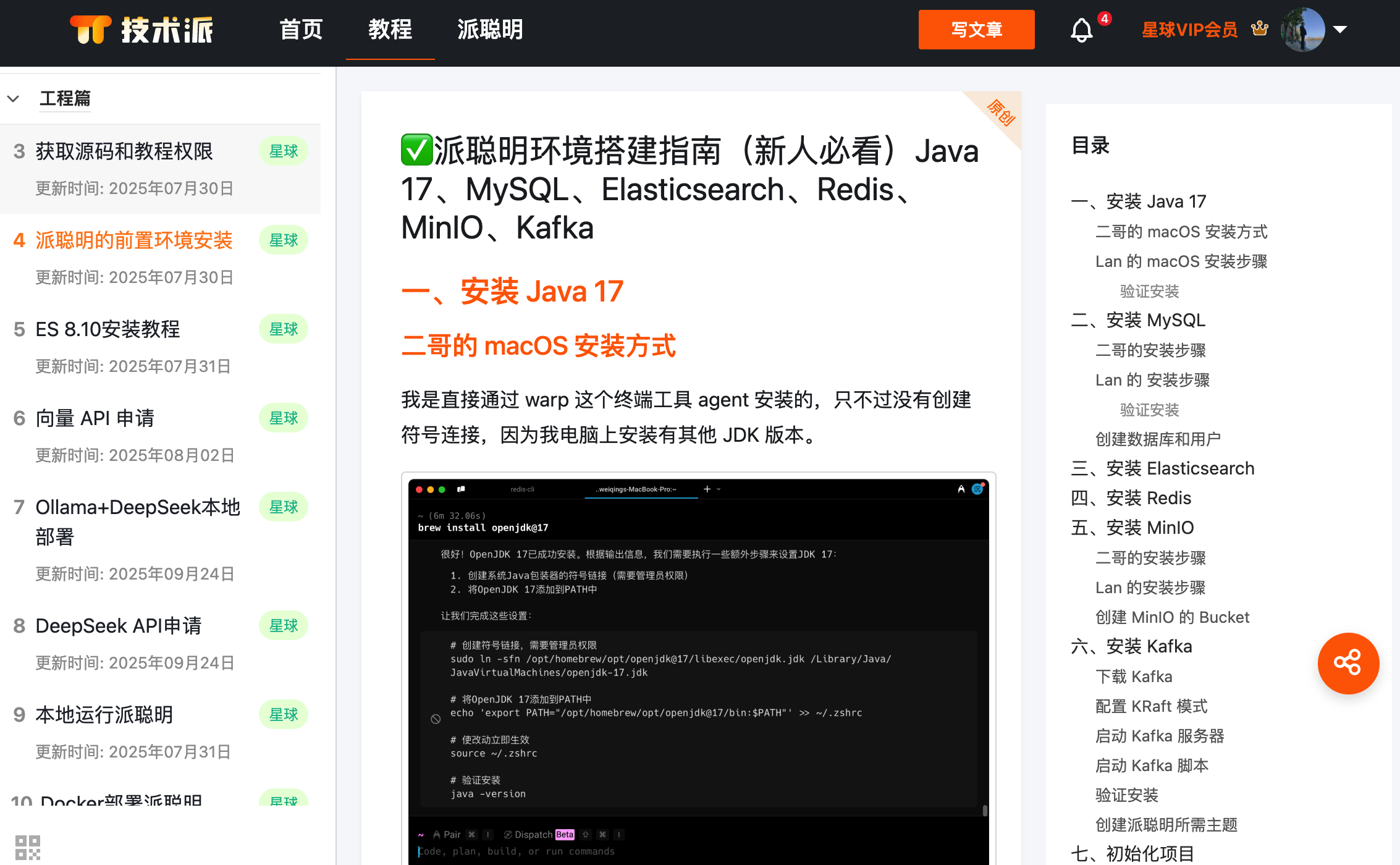
工程篇里的教程会告诉你需要安装哪些基础软件(JDK、Maven、Node.js、Docker),以及如何一键启动项目依赖的中间件(比如 Kafka、MinIO、MySQL、ElasticSearch、Redis 等)。
包括 embedding 和 llm 模型的 API 接入。
前端的启动说明,教程里也有。
或者直接使用 Docker 一键跑起来https://paicoding.com/column/10/10
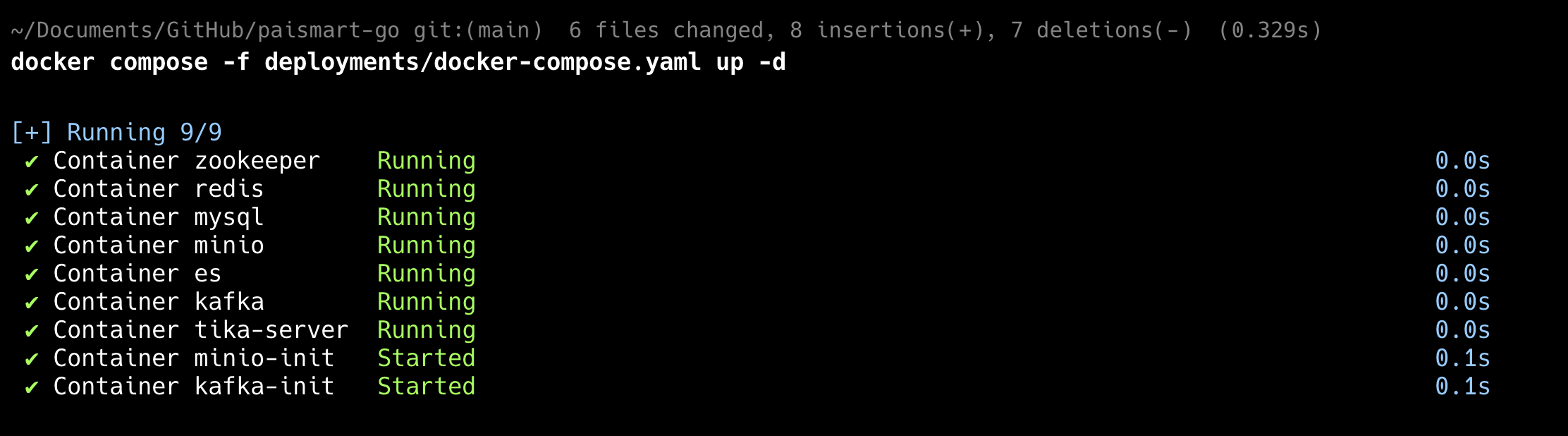
Go 版本的 Docker 搭建过程https://...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

42人已点赞
2 条评论
回复