


阿里飞猪一面(RAG),9道高频RAG高频面试题
老王透明的茶杯里,泡满了枸杞,我就瞅了一眼,少说也有 100 颗。
没等我回过来神,老王就直入主题:“你做 RAG 检索用的什么数据库?”
“MySQL。”
老王差点没把刚抿到嘴里的水喷到我帅气的脸上:“就 MySQL?向量检索你用 MySQL?”
“咋了王哥,MySQL 不配拥有向量吗?100 万条 chunk 我照样给它安排得明明白白。”
看老王气急败坏的样子,我笑了:“王哥,逗逗你啦,活跃活跃气氛嘛,这下我不紧张了。向量这块我用的是 ElasticSearch 了,既能做语义,又能做关键字存储,混合检索轻松搞定。😄”
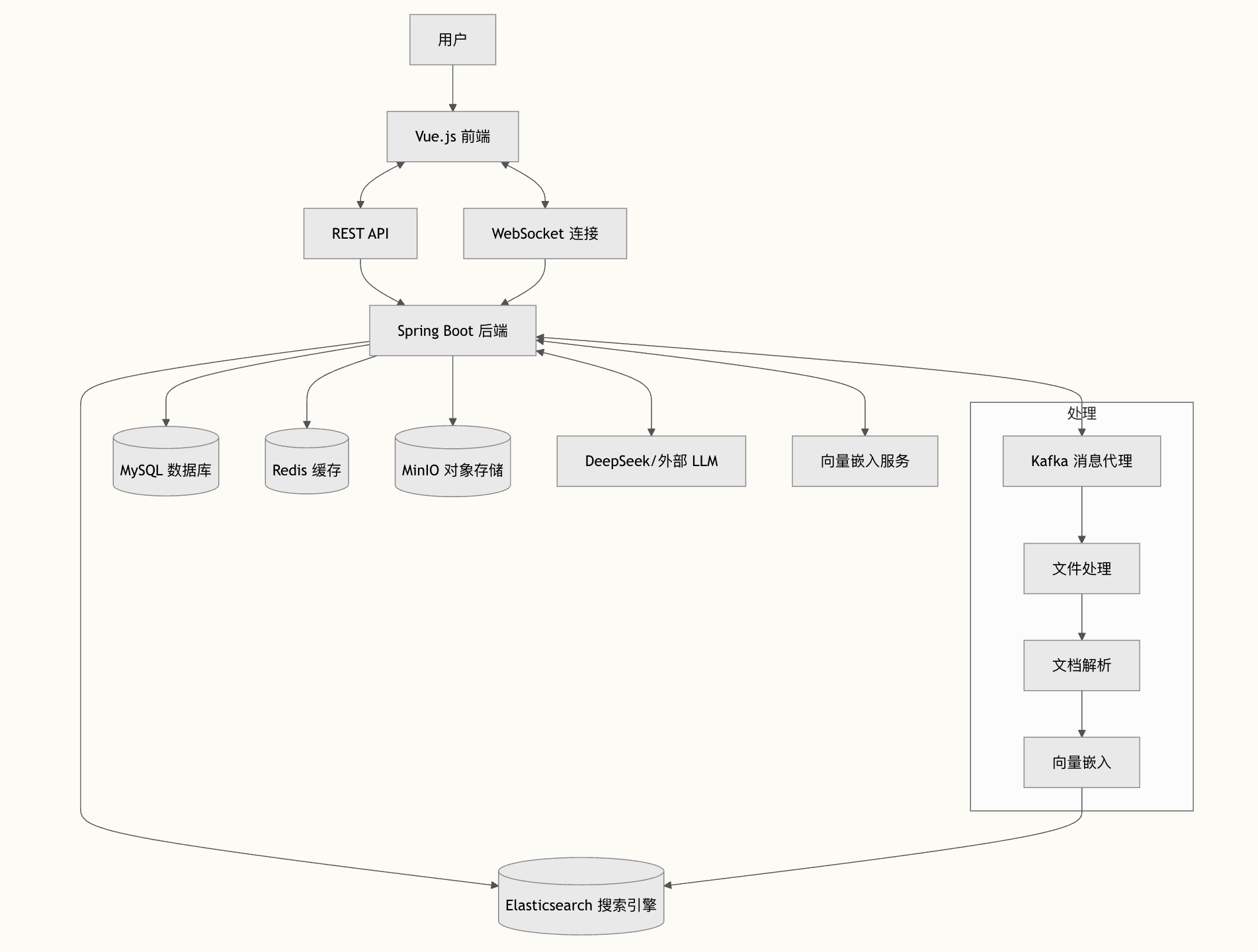
老王真是个好人啊,愣是没生气,仍然和颜悦色。问出了下一题:“你这个 RAG 系统,检索精确率怎么评估的?具体怎么测试?”
(内心 OS:这下面试有了,天底下所有的面试官都能像老王一样就好了呀。)
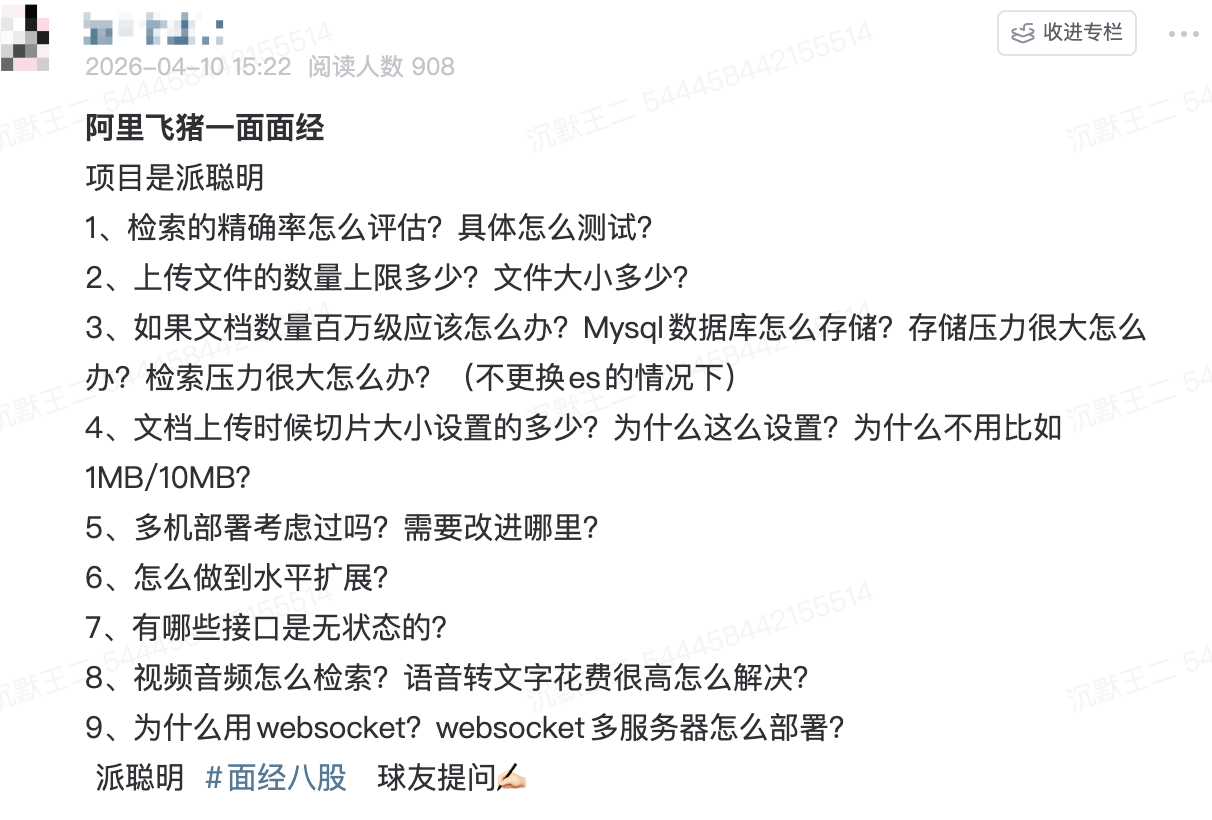
PS:以下题目来自派聪明 RAG 项目的真实面试题目,如上图所示,阿里飞猪一面。
content
01、检索精确率怎么评估的?具体怎么测试?
我说:“王哥,我在派聪明 RAG 里专门做过一轮评估。”
“评估检索质量,业界常用的指标有三个:精确率(Precision)、召回率(Recall)和 MRR(Mean Reciprocal Rank)。”
精确率看的是检索出来的文档里有多少是真正相关的。比如检索返回了 10 个 chunk,其中 7 个和问题相关,精确率就是 70%。
召回率看的是所有相关文档里,有多少被检索出来了。比如知识库里一共有 15 个相关 chunk,检索返回了 7 个,召回率就是 46.7%。
MRR 看的是第一个正确结果的排名,排名越靠前分越高。用户最关心的其实是“第一条结果是不是我要的”,MRR 就是衡量这个的。

具体怎么测试呢?
“我的做法是构建一个评估数据集。”
“先标注 200 到 500 组 QA 对,每组包含一个问题和对应的标准答案 chunk。然后把这些问题批量放到检索模块,拿到返回结果,和标注结果做对比,算上面三个指标。”
“派聪明 RAG 上线前我们跑了一轮评估,精确率从最初的 68% 优化到了 89%,主要靠两个手段:一个是换了更好的 embedding 模型,另一个是加了重排模型对检索结果做二次排序。”
老王追问:“重排模型用的哪个?”
“用的 bge-reranker-v2-m3,这个模型对中文语义的理解比较好,而且推理速度能接受,P95 延迟在 50ms 以内。”
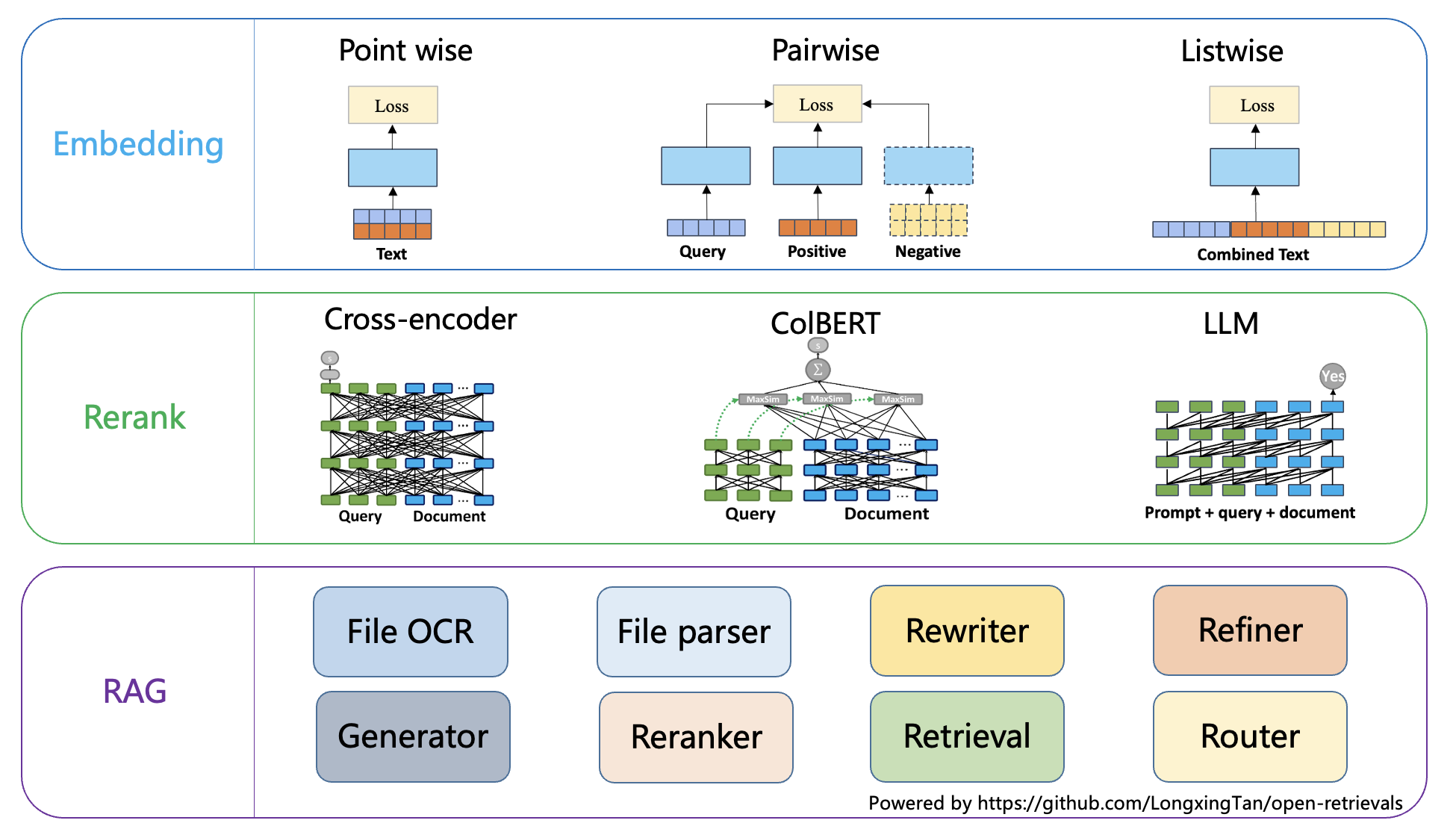
老王点点头:“评估体系搭得还可以。”
02、上传文件的数量上限多少?
老王接着问:“上传文件的数量上限是多少?文件大小多少?”
我说:“这个要分两层来说——业务层限制和系统层限制。”
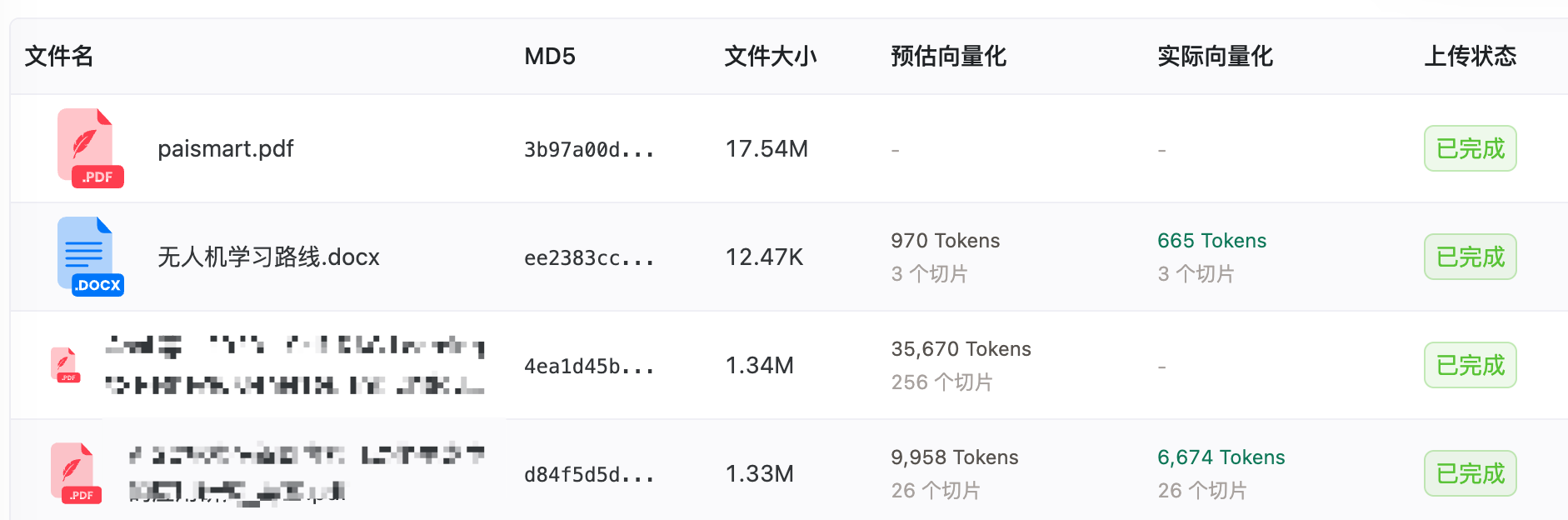
“业务层面,我们限制单次上传不超过 20 个文件,单文件不超过 50MB。大部分用户上传的是 PDF 和 Word,50MB 基本覆盖了 99% 的文档。”

“系统层面,真正的瓶颈在文档解析和向量化。一个 50MB 的 PDF 可能有几百页,解析成文本、切分成 chunk、逐个向量化,整个流程下来可能要几分钟。如果用户一次上传 20 个这种大文件,后台任务队列会堆积。”
“所以我做了异步处理。用户上传后立刻返回成功,后台用 Kafka 慢慢消化。前端有个进度条,处理完了会通知用户。”
老王追问:“如果有人恶意上传大量垃圾文件呢?”
“做了限流。按用户维度限制每天上传总量不超过 500MB,按 IP 维度限制并发上传数,以及做了每天的 Embedding 额度限制。另外文...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

9人已点赞
热门评论
10 条评论
回复