


食堂打饭时,同事问:你们天天说的 Embedding、Rerank 到底是啥?打饭阿姨抢着说:就是让LLM听懂人话。佩服佩服啊。
大家好,我是二哥呀。
不管是 Claude Code 还是 Codex,它们在读项目源码/读知识库的时候都很无敌,随便问一个问题,都能精准定位到对应的代码块/文档。
这是怎么做到的呢?
背后离不开 Embedding 的功劳。
今天这篇,我们从 Embedding 和 Rerank 的原理讲起,结合派聪明 RAG 和 PaiCLI Agent 两个项目的真实实现,把这两块知识彻底讲透。
01、为什么需要 RAG?
现在的模型能力已经非常强了,不管是 GPT-5.5 还是 Opus 4.7。
基本上日常的 Coding 和部分的文本都可以交给他们来完成了。
并且质量很高。
但有两个问题是 LLM 很难解决的。
第一个是知识截止。
模型训练完之后,它的知识就定格在那个时间点了。2026 年 5 月发生的事,一个 2025 年训练完的模型是不可能知道的。
第二个是私有数据盲区。
公司内部的文档、代码仓库、客户资料,这些没出现在训练数据里的东西,模型统统不认识。
解决办法目前有两个,一个是联网搜索,让 Agent 即时获取最新的知识。
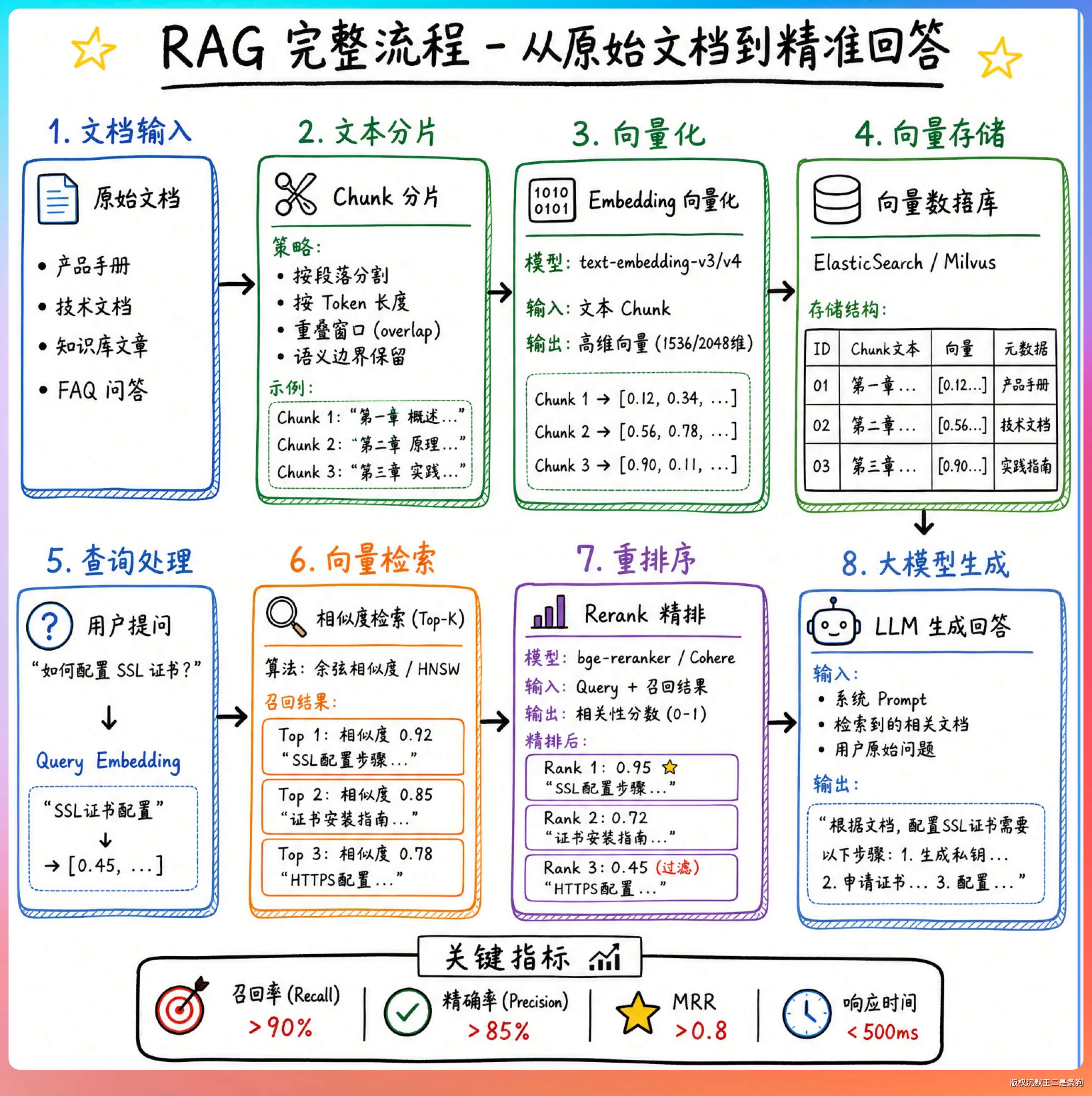
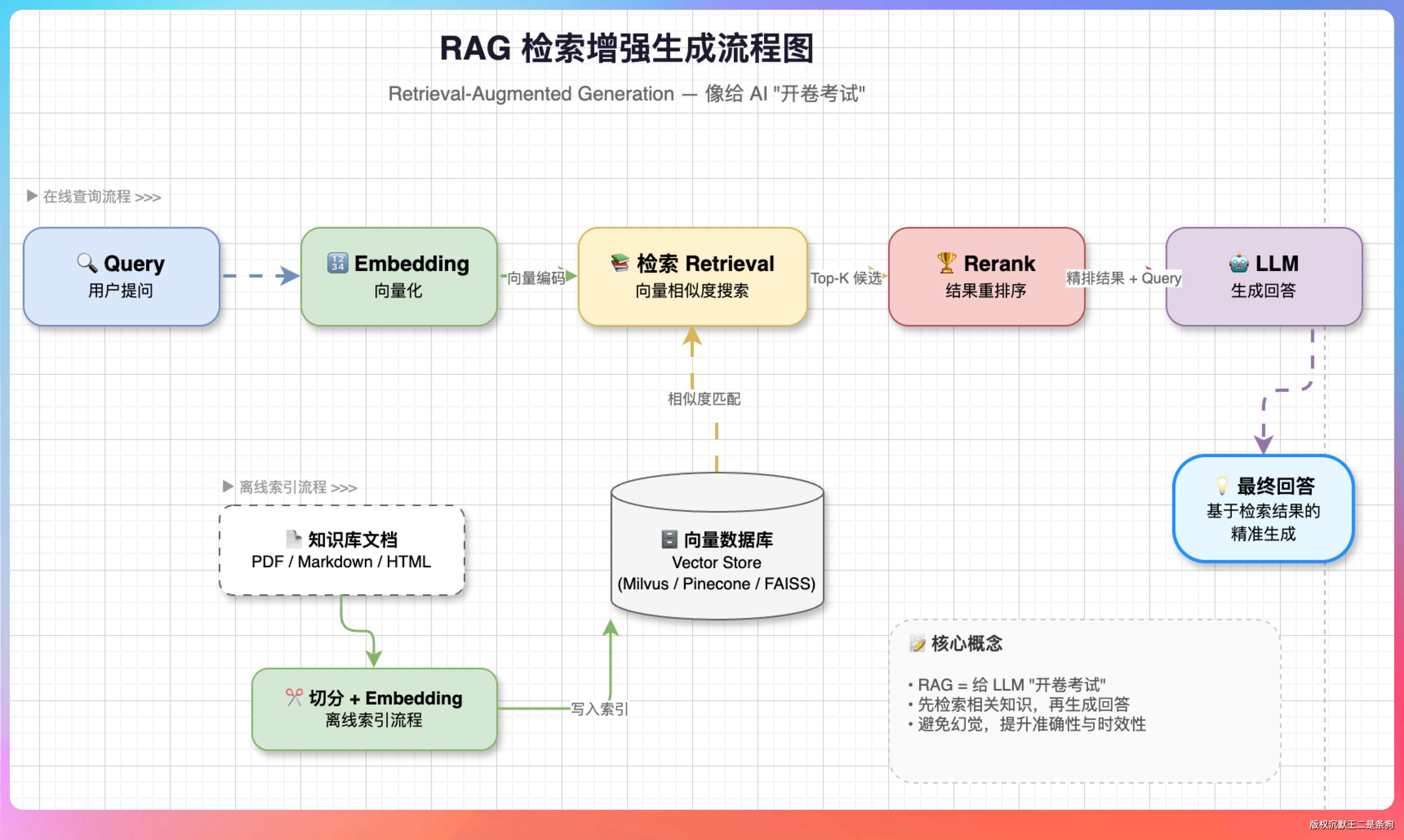
另外一个就是 RAG。思路很简单:问问题之前,先从知识库里把相关的内容检索出来,塞到 LLM 的上下文里,让它"开卷考试"。
这个检索过程的核心技术就是 Embedding。
02、Embedding 是什么?
Embedding 就是把文本变成一组向量,让计算机能用数学方式理解语义。
举个例子,王二是个沙雕和王二很可能不正常,在语义上是完全一样的。
Embedding 做的就是这件事,把这两句话各自变成一个 2048 维的向量(一组 2048 个浮点数),然后通过计算这两个向量之间的余弦相似度,得出它们"有多像"。
向量空间里,语义相近的文本会聚集在一起,语义不同的文本会远离。"苹果手机"和"iPhone"的向量距离很近,而"苹果手机"和"母猪会上树"的向量距离很远。
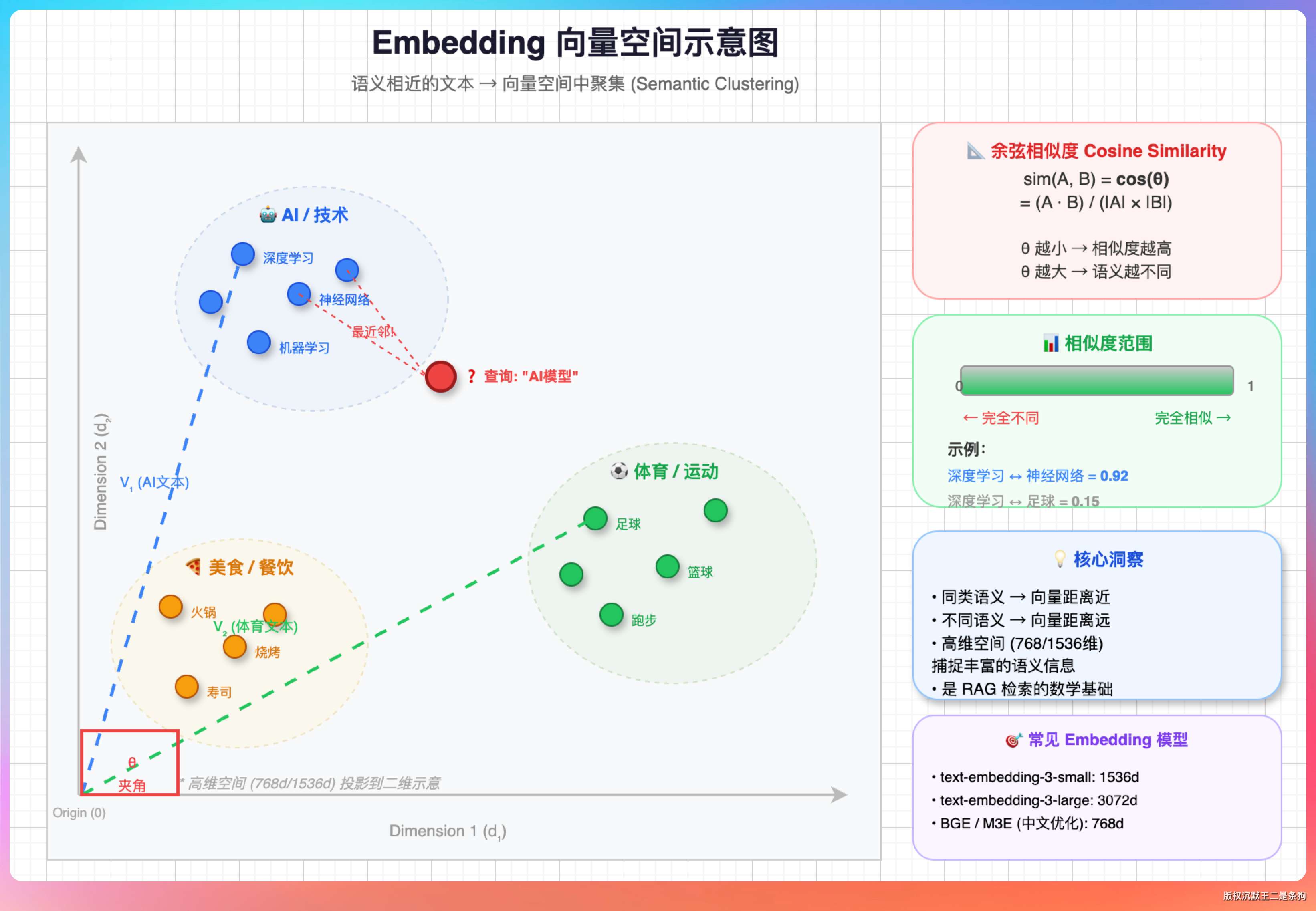
Embedding 模型用的是双塔架构(Bi-Encoder)。
Query 和文档各自独立编码成向量,两边互不干扰。
这种架构有一个巨大的好处:文档的向量可以提前算好存起来,查询的时候只需要算 Query 的向量然后做相似度比较就行了。
几百万条文档的检索,毫秒级完成。
03、如何做好 Chunk?
Embedding 模型有输入长度限制(一般 8192 个 token),不可能把一篇几万字的文档一口气塞进去。所以需要先把文档切成小块(Chunk),每块单独做 Embedding。
Chunk 切得好不好,直接决定了检索质量。
切太大,一个 Chunk 里混了好几个话题,检索的时候会带一堆无关信息。切太小,上下文断裂,LLM 拿到的片段前后不搭。
派聪明(PaiSmart)的分块策略采用了语义感知切分,默认 chunk 大小 512 字符,重叠 100 字符。切分的时候不是机械地按字数截断,而是用 HanLP 做中文分词,尽量在句子边界处切割。
具体来说分了四个层级:
- 第一层先按段落切(双换行符
\n\n) - 第二层如果段落太长就按句子切
- 第三层用 HanLP 分词器在词的边界处切
- 第四层实在没办法了才按字符切。
这样切出来的每个 Chunk 都是语义完整的。
重叠区域(Overlap)也很讲究。派聪明不是简单地取前一个 Chunk 的最后 100 个字符,而是做了语义感知的重叠,用 HanLP 的分词结果找到合适的句子边界,保证重叠部分不会把一个词从中间劈开。
PaiCLI 的分块策略完全不同,因为它处理的是代码而不是文档。
代码有天然的结构,文件、类、方法...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

3人已点赞
回复