


✅派聪明RAG面试题预测,31 道高频 AI 面试八股,1.2 万字 50 张手绘图,真diao打面试官
1.请详细描述完整的RAG系统架构,包括主要组件和数据流向?
RAG 系统本质上要解决一个问题:如何让 AI 能够基于企业内部的知识库来回答用户问题。所以整个架构设计围绕着"文件上传-文件存储-向量生成-答案生成"这条主线来展开。当用户上传文档后,我们首先通过 Upload 接口来处理上传文件,并支持分片上传避免大文件传输问题。然后很关键的一点是,我们没有选择同步处理,而是把文件处理任务丢到 Kafka 的消息队列里,这样用户上传完就能立即得到响应,不用等待漫长的处理过程。
接下来是文档解析环节, FileProcessingConsumer 作为 Kafka 消费者会异步处理这些任务。我们使用 Apache Tika 来解析各种格式的文档,比如 PDF、Word、Excel 等,然后通过 ParseService 把文档内容切分成小段,这样做的好处是既能保持语义的完整性,又能控制向量化的粒度。
向量化这块是整个 RAG 系统的核心, VectorizationService 会调用豆包的 Embedding API 把文本转换成向量表示。我们选择把这些向量存储在 Elasticsearch 中,主要是因为 ES 在向量检索方面的性能比较好,而且支持混合检索。
说到检索,这是 RAG 系统能否准确回答问题的关键。我们实现了混合检索策略,既有基于向量相似度的语义检索,也有传统的关键词检索,这样能够在不同场景下都有比较好的召回效果。特别重要的是,我们在检索时加入了权限控制,确保用户只能检索到自己有权限访问的文档。
生成这块,我们集成了 DeepSeek 大语言模型,通过 DeepSeekClient 来调用 API。这里有个技术细节就是我们支持流式响应,用户不用等到整个回答生成完才能看到结果,而是可以实时看到 AI 的回答过程,体验会好很多。
整个对话流程是通过 ChatHandler 来协调的,它会先调用检索服务找到相关文档,然后把这些文档作为上下文传给大语言模型,最后把生成的回答通过 WebSocket 实时推送给用户。我们还在 Redis 中维护了对话历史,这样 AI 能够理解上下文,进行多轮对话。
权限控制方面,我们实现了基于组织标签的多租户架构。通过 OrgTagAuthorizationFilter 确保用户只能访问自己组织内的文档,实现数据的安全隔离。
总的来说,这套 RAG 架构的设计理念就是要在保证准确性的前提下,尽可能提升用户体验和系统性能,同时确保企业级的安全性。
2.在设计RAG系统时,如何选择合适的向量数据库?Elasticsearch、Pinecone等有什么区别?
首先说说我们为什么在派聪明中选择了 Elasticsearch。第一个原因是我们团队对 ES 比较熟悉,第二个原因是 ES 的混合检索能力很强,既支持传统的全文检索,也支持向量检索,这对 RAG 系统来说是个很大的优势。
但是说实话,ES 在纯向量检索性能上并不是最优的选择。如果系统主要是向量相似度搜索,专门的向量数据库会更合适。比如 Pinecone,它是专门为向量检索设计的云服务,性能确实很不错,而且使用起来很简单,基本上开箱即用。但是有个问题就是成本,特别是数据量大的时候,费用会比较高。而且作为云服务,数据安全和合规性可能是一些企业需要考虑的问题。
就我个人的体验来说,可以先用 ES 这样的通用方案快速验证业务价值,等业务稳定后再根据性能瓶颈考虑迁移到专门的向量数据库。这样既能快速上线,又能控制技术风险。毕竟 RAG 系统的核心价值还是在业务逻辑和数据质量上,选择合适的就行,不一定非要追求最新最炫的技术。
3.RAG系统中的混合检索是什么?如何实现?
混合检索简单来说就是把不同的检索方法结合起来,取长补短,提高检索的准确性和召回率。
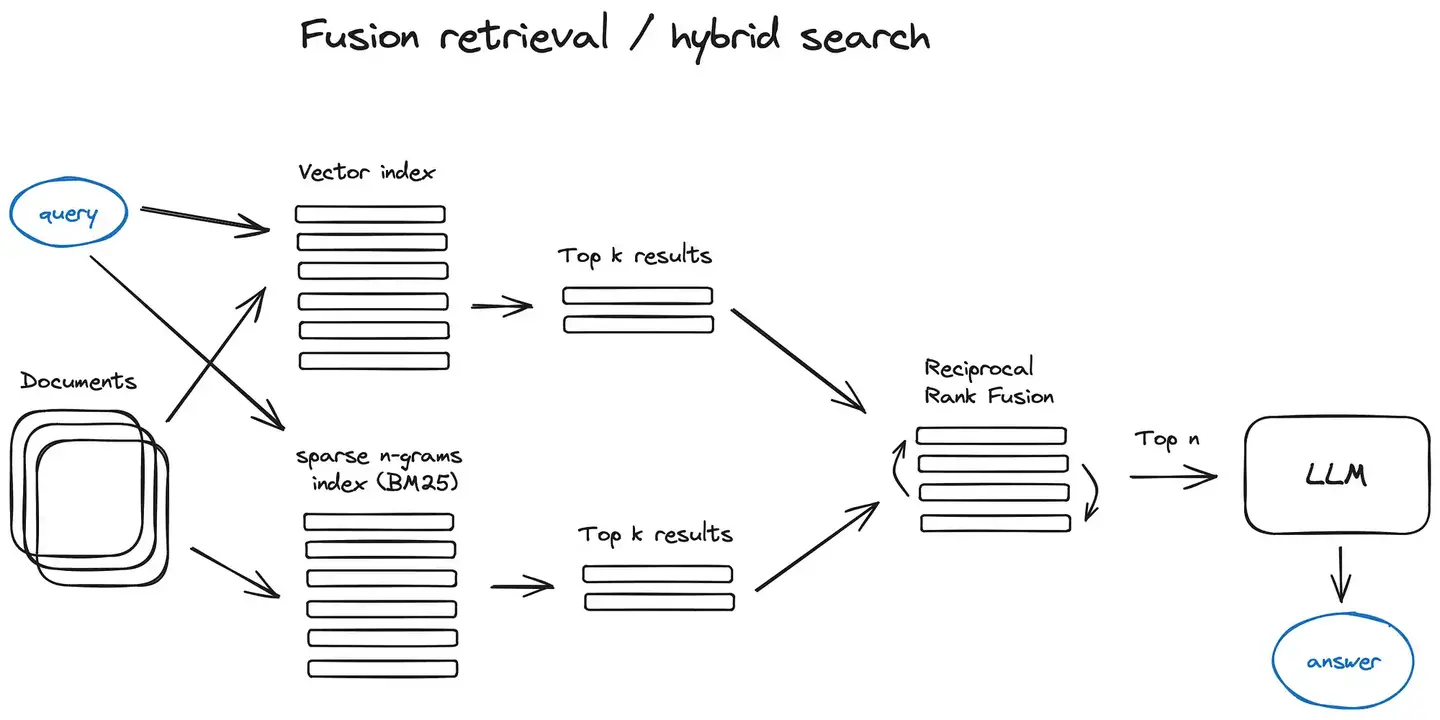
在派聪明项目中,混合检索主要是结合了两种检索方式:语义检索和关键词检索。语义检索就是基于向量相似度的,它能够理解查询的语义含义,即使用词不完全匹配也能找到相关内容。比如用户问"如何提升工作效率",它能找到包含"提高生产力"、"优化流程"这样语义相关的文档。而关键词检索就是传统的全文检索,它对精确匹配很有效,特别是一些专业术语、人名、地名这种。
在技术实现上,我们是这样做的。首先对用户查询同时执行向量检索和全文检索,然后把两个结果集合并。这里有个关键问题就是如何合并和排序。我们采用的是加权融合的方式,给语义检索和关键词检索分别设置权重,然后计算综合得分。
第一阶段:KNN 向量召回
// KNN 向量召回阶段
s.knn(kn -> kn
.field("vector")
.queryVector(queryVector) // 查询向量
.k(recallK) // 召回数量(topK * 30)
.numCandidates(recallK) // 候选数量
);
第二阶段:关键词过滤
// 必须命中关键词 + 权限过滤
s.query(q -> q.bool(b -> b
.must(mst -> mst.match(m -> m.field("textContent").query(query))) // 关键词匹配
.filter(f -> f.bool(bf -> bf
.should(s1 -> s1.term(t -> t.field("userId").value(userDbId))) // 用户权限
.should(s2 -> s2.term(t -> t.field("public").value(true))) // 公开文档
.should(s3 -> /* 组织权限 */) // 组织权限
))
));
第三个阶段:BM25重排序
// BM25 rescore 重排序
s.rescore(r -> r
.windowSize(recallK)
.query(rq -> rq
.queryWeight(0.2d) // KNN分数权重20%
.rescoreQueryWeight(1.0d) // BM25分数权重100%
.query(rqq -> rqq.match(m -> m
.field("textContent")
.query(query)
.operator(Operator.And) // 严格关键词匹配
))
)
);
具体的算法是这样的:假设一个文档在语义检索中的得分是 0.8,在关键词检索中的得分是 0.6,我们可以设置语义检索权重为 0.7,关键词检索权重为 0.3,那么最终得分就是 0.8*0.7 + 0.6*0.3 = 0.74。当然这个权重可以根据实际效果来调整。
在此基础上,我们还加入了权限过滤的逻辑。用户只能检索到自己有权限访问的文档,这个过滤是在检索结果合并之后进行的。
// 三种权限访问模式
.should(s1 -> s1.term(t -> t.field("userId").value(userDbId))) // 自己的文档
.should(s2 -> s2.term(t -> t.field("public").value(true))) // 公开文档
.should(s3 -> /* 组织层级权限 */) // 组织文档
4.解释向量embedding的维度选择对系统性能的影响?为什么我们选择2048维而不是384维?
首先,从模型能力角度来看,我们使用的是火山引擎的 doubao-embedding-text-240515 模型。 根据guanfang文档,这个模型的最高维度向量是 2048 维,支持 512、1024 降维使用。我们选择 2048 维实际上是在使用这个模型的原生最高维度输出,这样能够最大程度地保留模型训练时学到的语义信息。
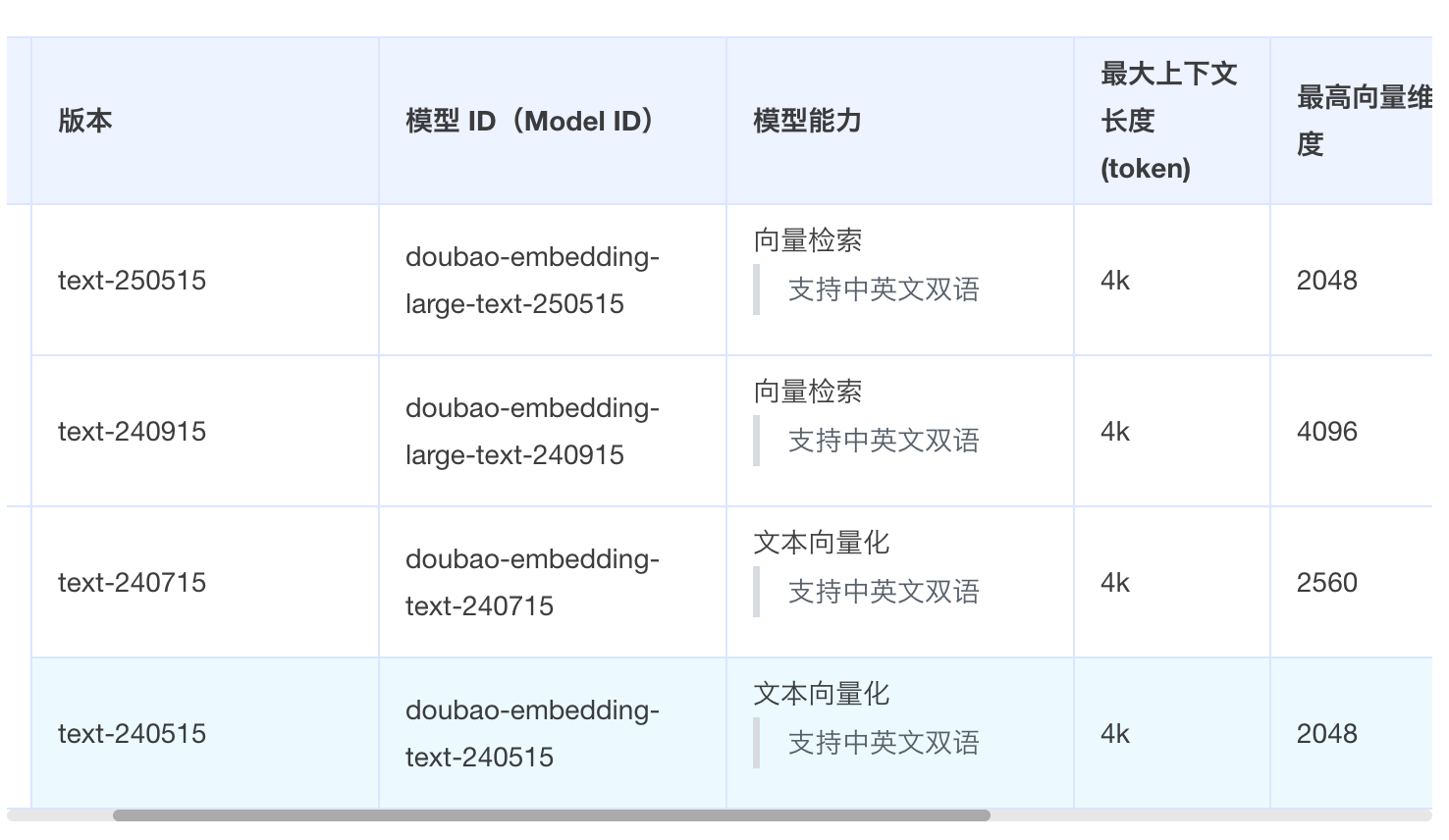
从语义表达能力来说,维度越高,向量能够表达的语义信息就越丰富。2048 维相比 384 维有着显著的优势。高维向量能够在语义空间中更精确地区分不同概念之间的细微差别,这对于 RAG 系统来说至关重要。
当然,高维度意味着成本更高。
从技术实现角度,我们在 ES 的 knowledge_base.json 中也配置了向量字段为 2048 维,使用 cosine 相似度计算。这个配置与豆包的 embedding 模型完全匹配。

5.如何解决向量检索中的"语义漂移"问题?
语义漂移是 RAG 系统中一个非常关键的问题,简单来说就是随着时间推移,向量表示的语义可能会发生偏移,导致检索效果下降。
在派聪明项目中,我们采用了多层次的解决策略。第一个层面是模型版本管理。我们在 EsDocument 中专门设计了 modelVersion 字段来记录每个向量是由哪个版本模型生成的。这样当我们升级向量模型时,可以识别出哪些向量需要重新生成。

第二个层面是增量更新策略。我们不是一次性替换所有历史向量,而是采用渐进式的方法。当检测到某些文档的检索效果明显下降时,我们会优先对这些文档进行重新向量化。这个过程可以通过用户反馈和检索点击率来触发。
第三个层面是混合检索的优势。我们结合了语义检索和关键词检索。即使语义向量出现漂移,关键词检索仍然能够提供稳定的基准效果。
6.在多租户RAG系统中,如何设计权限控制和数据隔离?
首先,我们采用了多层级的权限控制架构。在用户层面,系统支持普通用户和管理员两种角色,管理员拥有全局访问权限,可以管理所有用户的组织标签分配。在组织层面,我们设计了灵活的组织标签系统,每个用户可以属于多个组织,并且有一个主组织标签。特别值得一提的是,系统为每个用户自动创建私人组织标签(PRIVATE_用户名),确保用户有独立的私人空间。
在数据存储层面,我们设计了三个关键字段来实现数据隔离:userId 标识文档所有者,orgTag 标识文档所属组织,isPublic 标识是否为公开资源。
在文件上传时,系统会根据用户的主组织标签自动为文档分配组织标...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

71人已点赞
热门评论
220 条评论
回复