


✅派聪明 RAG 项目的ElasticSearch混合检索精讲
大家好,今天我们来一起学习下派聪明中非常核心的一个功能——混合检索。我会给大家一步步讲清楚,看懂派聪明是如何结合“关键词搜索”和“语义搜索”这两种技术实现 RAG 中关键的 Retrieval。

一、关键词搜索和语义搜索
在开始之前,我们需要搞清楚为什么不只用一种搜索技术,关键词搜索是什么,语义搜索又是什么。
关键词搜索需要将文档和查询都拆解成一个个独立的词语,然后通过匹配这些词语来计算相关性。依赖于一种名为“倒排索引”的数据结构,可以瞬间找到包含特定关键词的所有文档。
在没有搜索引擎前,我们搜内容是这样的,打开一个网址,获取网站的内容,然后输入关键词进行匹配:
document -> to -> words
通过文章,获取里面的关键词,这就是所谓的“正向索引”,英文名为 forward index。
后来,我们希望输入一个关键词,找到含有这个关键词的有关文章:
word -> to -> documents
我们把这种索引,称为 inverted index,直译过来叫反向索引,国内习惯翻译成“倒排索引”。
像技术派的首页,就用 ES 做过倒排的查询。
当用户的查询意图明确,用词精准时,关键词查询能提供精准、快速的结果。
于此同时,关键词搜索也有自己的局限性:刻板,缺乏深层的理解能力。无法理解同义词、近义词或上下文。例如,用户搜索“如何降低电脑温度”,它可能找不到一篇标题为“笔记本散热技巧”的优质文章,因为两者没有共同的关键词。
那什么是语义搜索呢?
语义搜索需要利用深度学习模型(Embedding Model),将文本的整体含义转换成一个高维空间中的数学向量。通过计算向量之间的距离(如余弦相似度),来判断文本在语义层面的相似性。
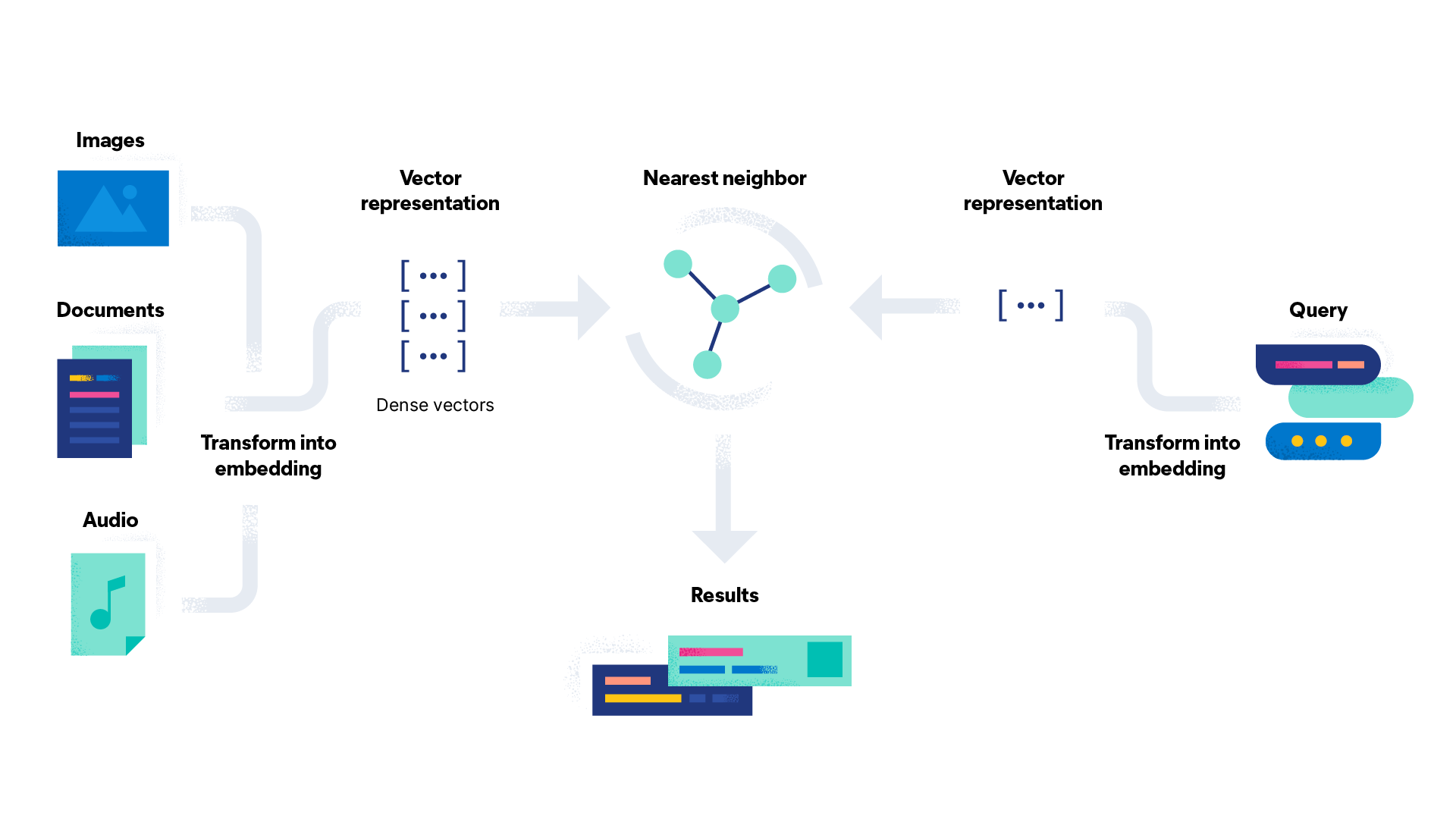
也就是说,语义搜索由向量搜索提供支持,具备极高的智能化水平。能够跨越文字的障碍,理解深层语义。对于上一个例子,语义搜索能准确判断“降低电脑温度”和“笔记本散热技巧”在语义上具有高度的一致性。
当然了,语义搜索的结果有时不够聚焦。它可能返回一篇语义高度相关、但恰恰缺少了用户最关心的某个核心关键词的文档,导致结果“看似相关,实则无用”。
派聪明的目标是成为一个专业的智能知识库问答系统。它既需要能理解用户模糊、口语化的自然语言查询,又必须保证返回结果的专业性和准确性,确保关...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

33人已点赞
热门评论
26 条评论
回复