


阿里云 OCR+LiteParse,让扫描件 PDF 也能被 RAG 检索到
大家好,我是二哥呀。
做 RAG 的小伙伴大概都被同一个东西卡住过:一份扫描件 PDF,或者一张截图 PDF,结果检索的时候怎么都搜不到内容。
我在做派聪明(PaiSmart,一个企业级 RAG 知识库)的时候就遇到过这个问题。
不过今天我找到了一个不错的解决方案,用 LlamaIndex 开源的 LiteParse,一条命令就能把扫描件里的文字 OCR 出来了,不需要 API Key,解析速度还很快。
这篇就来详细的讲一讲。
LiteParse 到底是什么、lit 命令怎么用、"空间文本解析"的思路,以及我是怎么把它接进派聪明的、踩了哪些坑。
系好安全带,我们粗粗粗发~
01、LiteParse 是什么
LiteParse 是 LlamaIndex 团队在 2026 年 3 月 19 日开源的一个文档解析工具,Apache 2.0 协议,仓库地址是
LlamaIndex 大家应该不陌生,他们之前有个明星产品叫 LlamaParse,专门解析复杂文档,效果很好,但是云服务,要上传文件、要付费、要联网。
LiteParse 是把 LlamaParse 里"核心的处理能力"抽出来,做成了一个完全本地运行的版本。
LiteParse 的定位是本地、轻量、快。
整个核心用 Rust 重写过,底层靠 PDFium 渲染 PDF,靠 Tesseract 做 OCR,跑在自己的机器上,没有任何云端调用,不需要 API Key,断网也能用。
它适合处理结构相对简单的文档,追求的是低延迟,专门为 AI Agent 这种"快速读一遍、需要时再细看"的迭代模式优化。
LlamaParse 处理的是那种特别难啃的文档,比如密集的表格、多栏排版、图表、手写字、质量很差的扫描件。
LiteParse 支持的格式包括:
- **PDF:**直接走 PDFium 做空间文本解析,扫描页和内嵌图片会自动触发 OCR
- Office 文档:Word、PPT、Excel、CSV 这些,先用 LibreOffice 转成 PDF,再走同一套解析管道
- 图片:PNG、JPG、TIFF、WebP 等,先用 ImageMagick 转成 PDF,再 OCR
02、lit 命令行
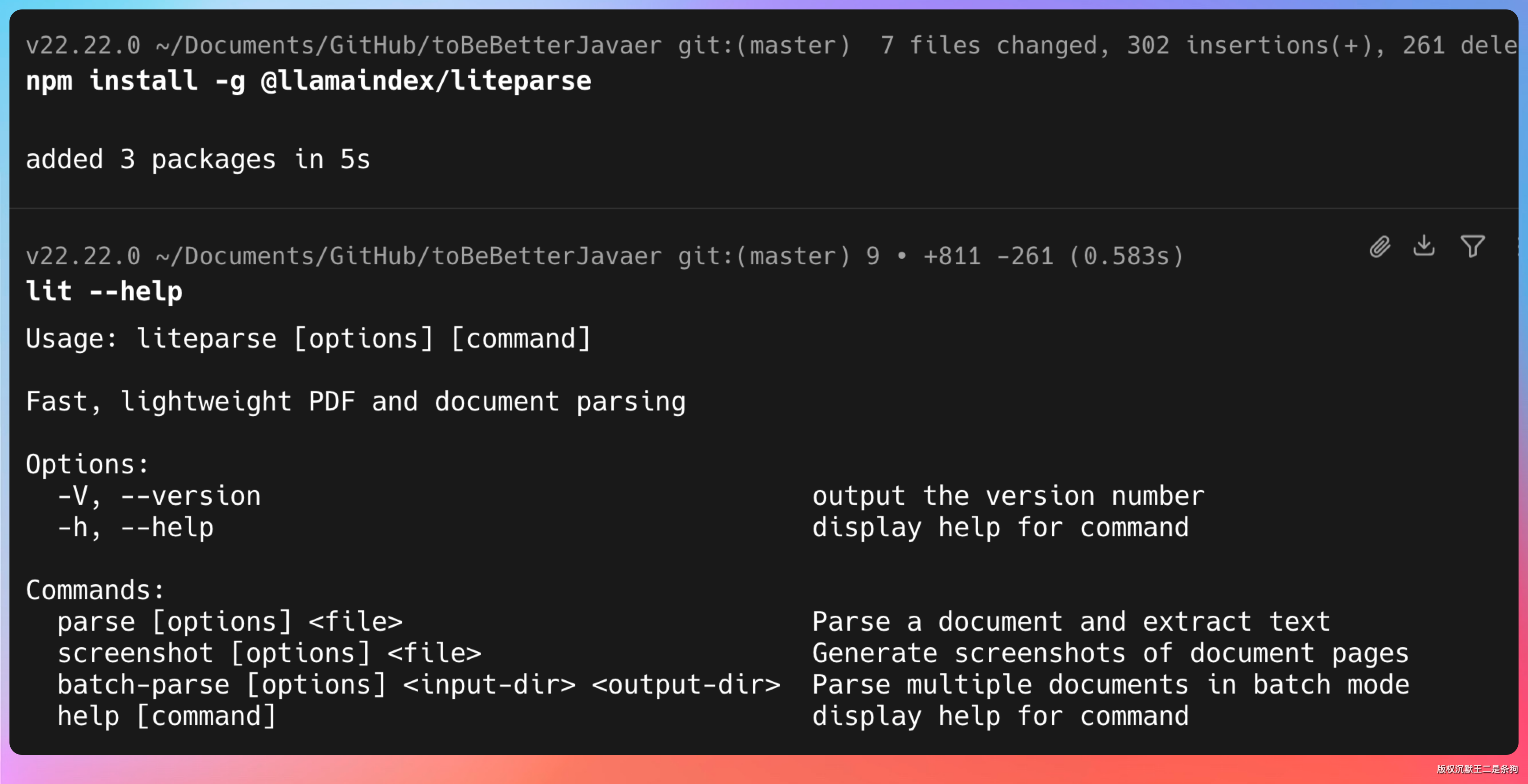
LiteParse 提供了多种安装方式,npm、pip、cargo 都可以,装完之后的命令行工具统一叫 lit。
npm i -g @llamaindex/liteparse
# 或者 Python
pip install liteparse
# 或者 Rust
cargo install liteparse
装完跑一下最基础的解析命令,把一份 PDF 直接转成文本:
lit parse docs/paismart.pdf
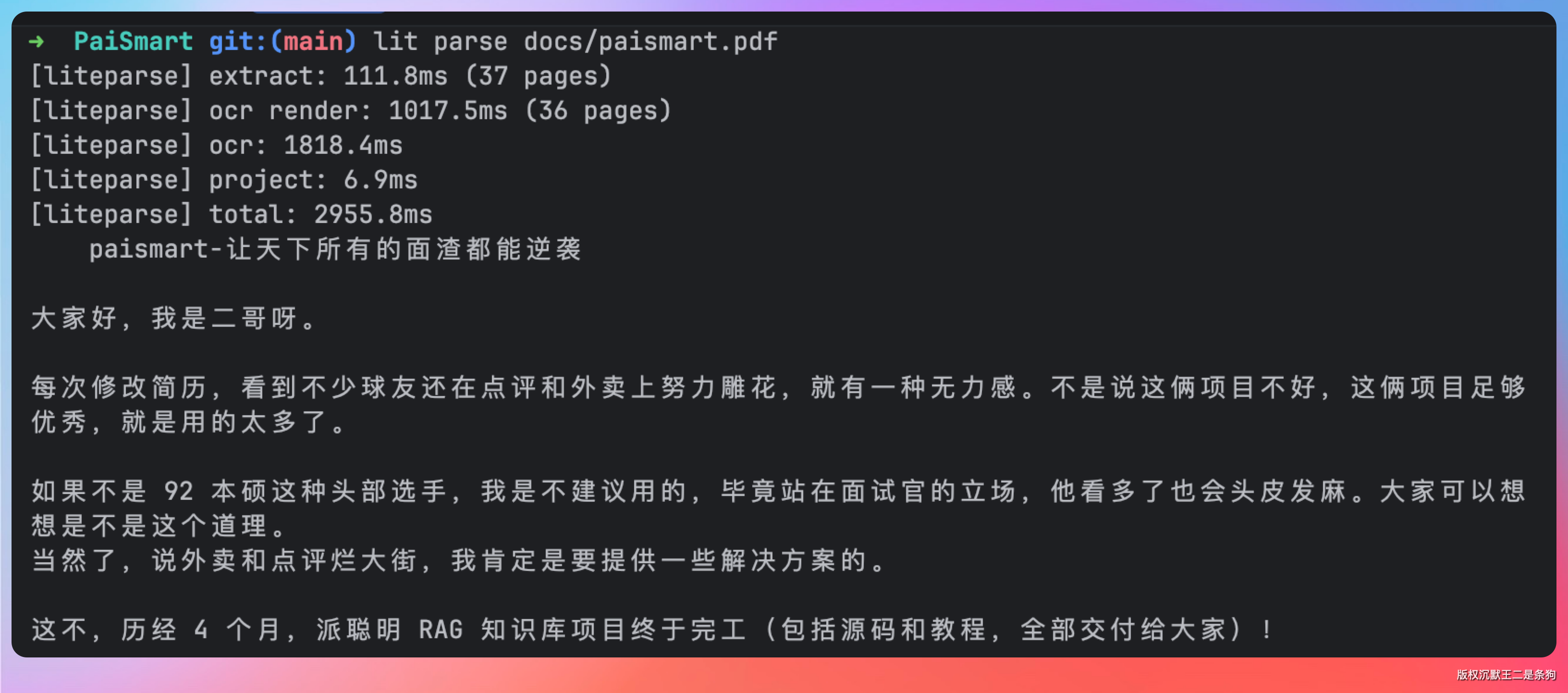
它会把解析出来的文本直接打到标准输出。天然能跟 Unix 的管道串起来,比如想在一份报告里找包含 table 的行,一条命令就够了:
lit parse docs/paismart.pdf | grep "table"
远程 PDF 也可以直接用 curl 拉下来喂给它:
curl -sL https://example.com/report.pdf | lit parse -
要结构化输出就加 --format json,再用 -o 指定输出文件:
lit parse document.pdf --format json -o output.json
JSON 输出里不只有文字,还带了每一段文本的边界框(bounding box)坐标,以及页码。
lit parse 的可选参数包括:
--target-pages "1-5,10":只解析指定页码,调试大文件的时候很省时间--no-ocr:关掉 OCR,纯文本 PDF 用这个能快不少--ocr-language:指定 OCR 语言包,中文要写chi_sim--ocr-server-url:指定外部 OCR 服务地址,不填就用内置 Tesseract--dpi:渲染分辨率,影响 OCR 精度和速度--num-workers:并行 worker 数,多核机器能加速--max-pages:最多解析多少页,防止超大文件拖垮进程--password:解密加密 PDF
除了 parse,还有两个命令也常用。一个是批量解析整个目录:
lit batch-parse ./input-directory ./output-directory
另一个是生成页面截图,这个是专门为 Agent 设计的:
lit screenshot document.pdf -o ./screenshots
03、把 LiteParse 接进派聪明
先说一下派聪明RAG的向量过程。
用户上传文件,然后往 Kafka 丢一个处理任务,由消费者监听消费,调用解析服务把文件切成一个个文本块(chunk),算好 embedding 向量,最后同步到 Elasticsearch 创建索引。
LiteParse 接的就是"解析"这一环。
派聪明原来用的是 Apache Tika 做通用文档解析,Tika 处理纯文本 PDF 没问题,但碰到扫描件就完蛋。
所以接入 LiteParse 势在必行。
由于 LiteParse 是个命令行工具,所以我们这次的做法是用 ProcessBuilder 起一个子进程,把 PDF 写到临时文件,通过命令行里指定 JSON 输出,跑完再读一下这个 JSON。
List<String> command = new ArrayList<>();
command.add(liteParseCommand); // lit
command.add("parse");
command.add(inputPath.toString()); // 临时 PDF 路径
command.add("--format");
command.add("json");
command.add("--output");
command.add(outputPath.toString()); // 临时 JSON 路径
command.add("--max-pages");
command.add(String.valueOf(liteParseMaxPages));
command.add("--dpi");
command.add(String.valueOf(liteParseDpi));
// OCR 语言:中文简体 + 英文
command.add("--ocr-language");
command.add(liteParseOcrLanguage); // chi_sim+eng
command.add("--quiet");
第一,超时控制。LiteParse 解析大文件或者跑 OCR 的时候可能很慢,子进程不能无限等。如果超时了就 destroyForcibly() 强制杀掉。
第二,标准输出和错误输出要重定向到文件。子进程的 stdout 和 stderr 如果写满了缓冲区进程会卡死。所以把它们分别重定向到两个临时文件,解析失败的时候记录到日志,方便排查。
第三,临时文件一定要清理。每次解析会创建输入 PDF、输出 JSON、stdout 日志、stderr 日志四个临时文件,所以要用 finally 块兜底,无论成功失败都把它们删掉。
解析完读 JSON 这一步,做了页级切分。
前面提过,LiteParse 的 JSON 输出里每一段文本都带页码。所以我们就按页拆开,一页一页地切 chunk,并且把页码记到每个 chunk 上:
for (LiteParsePage page : pages) {
String pageText = page.text();
if (pageText == null || pageText.isBlank()) {
continue;
}
List<String> childChunks = splitTextIntoChunksWithSemantics(pageText, chunkSize);
savedChunkCount = saveChildChunks(
fileMd5, childChunks, userId, orgTag, isPublic, savedChunkCount, page.pageNumber()
);
}
为什么要保留页码?
因为 RAG 检索命中之后,用户如果想知道"这段话出自原文档第几页",有了页码就能做溯源定位。
而且按页切分还有个好处,一个 chunk 不会横跨两页,语义上更干净,不会把第 3 页的结尾和第 4 页的开头硬凑在一起。
派聪明用的是"父文档-子切片"加语义重叠的策略:先按段落和句子边界切,太小的块会合并,相邻块之间留 100 字符的语义重叠(overlap),中文长句还会用 HanLP 分词在词义的边界上切割,避免把一个词切成两半。
配置是这样的:
file:
parsing:
chunk-size: 512
overlap-size: 100
min-chunk-size: 100
pdf:
engine: liteparse
liteparse:
command: lit
ocr-enabled: true
ocr-language: chi_sim+eng
dpi: 150
max-pages: 1000
timeout-seconds: 300
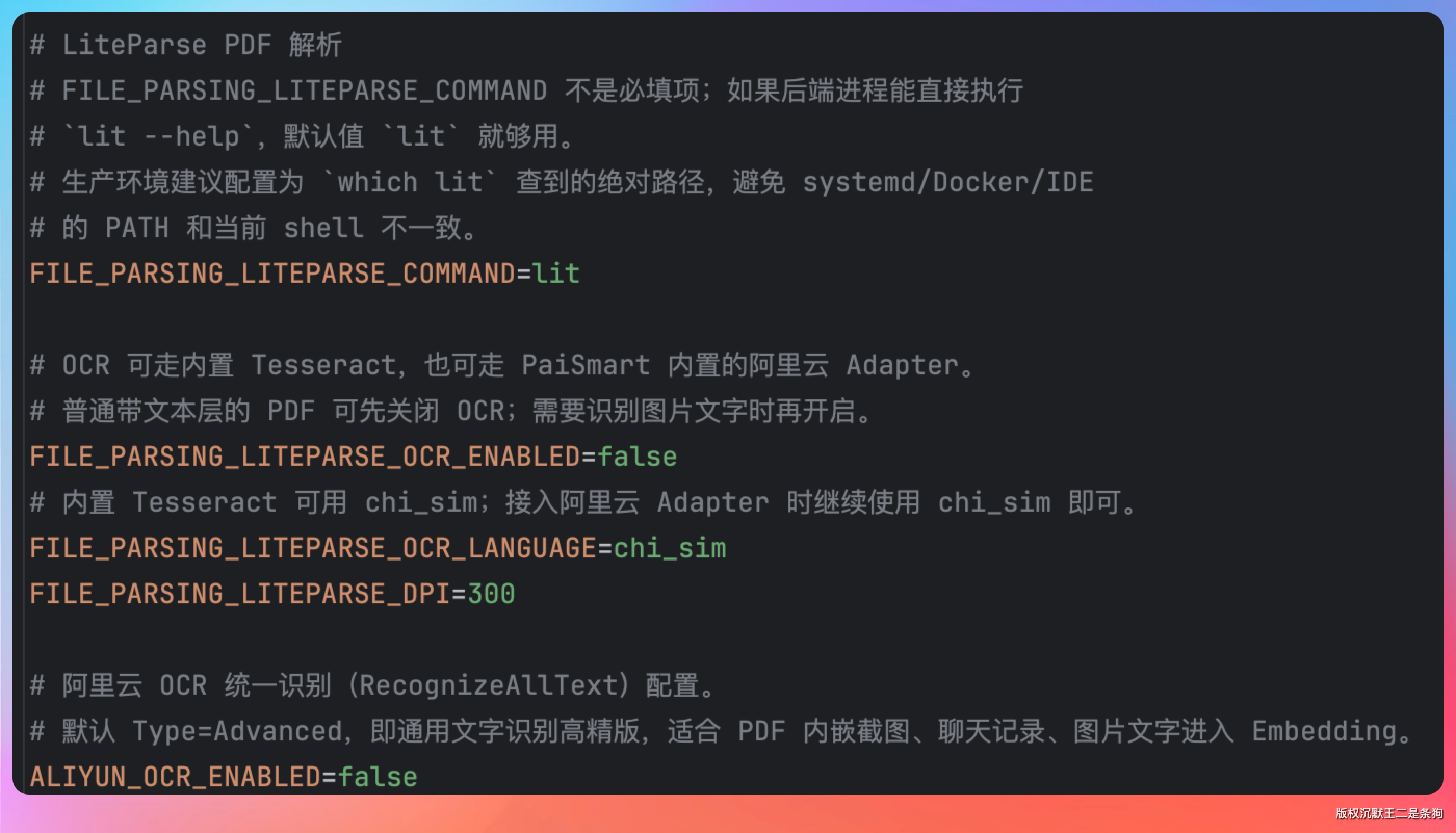
整套配置我都做成了可外部覆盖的环境变量,比如 lit 命令的路径、OCR 语言、DPI、超时时间,部署到不同环境改个环境变量就行,不用动代码。
05、图片 PDF 实测
接上 LiteParse 之后,我们还拿 paismart.pdf 这份文件来做测试,让 LiteParse 走内置的 Tesseract 把图片里的文字识别出来。
我们先来做一个测试。
TESSDATA_PREFIX="$HOME/Library/Application Support/tesseract-rs/tessdata" \
lit parse docs/paismart.pdf \
--target-pages 1 \
--dpi 300 \
--ocr-language chi_sim \
--quiet
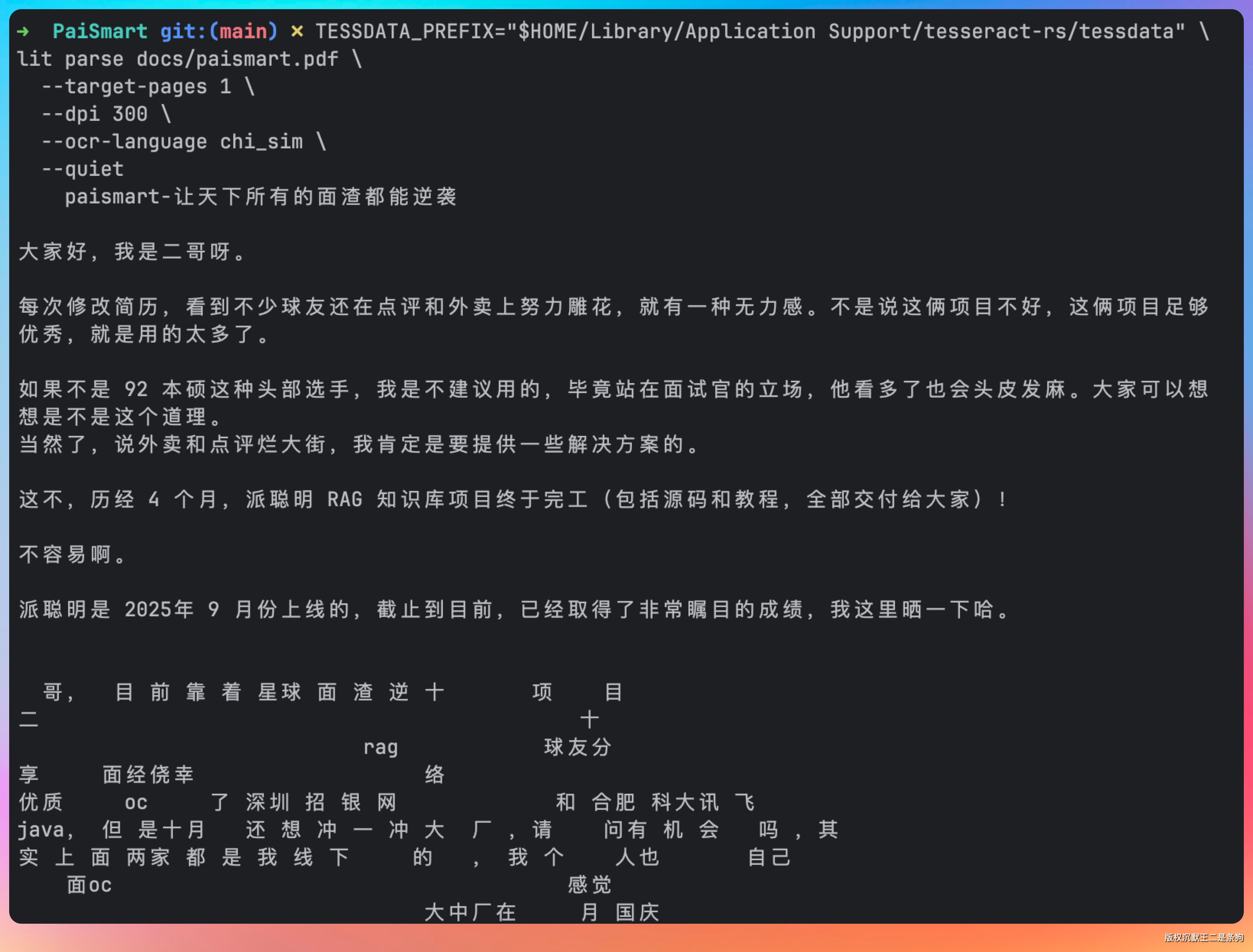
原始图片是这个样子。
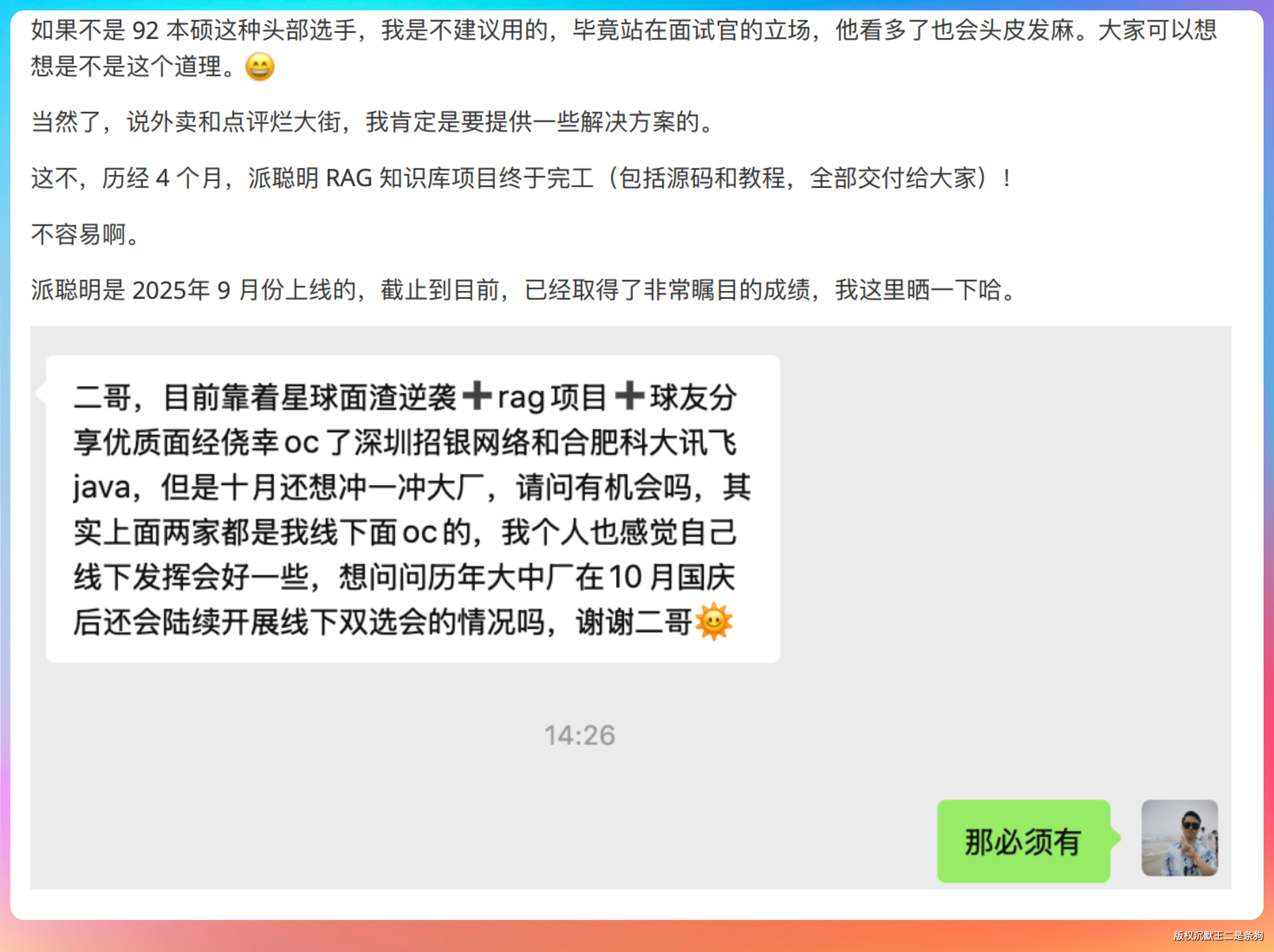
虽然解析结果不是特别理想,但基本上是可用状态了。
对吧?
LiteParse 不是无脑对每一页都 OCR。
它有一套自己的判断,只对那些文本稀疏、或者字体区域有乱码的页面才触发 OCR,纯文本页面直接走 PDFium 提取。
这里多说一句 DPI 这个参数。
DPI 越高,渲染出来的图片越清晰,OCR 越准,但每一页的处理时间和内存占用都会更多。 300 对大部分资料够用。
还有中文语言包的坑得提醒一下。
内置的 Tesseract 要识别中文,得装 chi_sim 语言包,配置里 ocr-language 写成 chi_sim+eng 表示中英文混合识别。
macOS 用户可以这样安装:
mkdir -p "$HOME/Library/Application Support/tesseract-rs/tessdata"
curl -L -o "$HOME/Library/Application Support/tesseract-rs/tessdata/eng.traineddata" \
https://github.com/tesseract-ocr/tessdata_fast/raw/main/eng.traineddata
curl -L -o "$HOME/Library/Application Support/tesseract-rs/tessdata/chi_sim.traineddata" \
https://github.com/tesseract-ocr/tessdata_fast/raw/main/chi_sim.traineddata
Linux可以:
mkdir -p /usr/local/share/tessdata
curl -L -o /usr/local/share/tessdata/eng.traineddata \
https://github.com/tesseract-ocr/tessdata_fast/raw/main/eng.traineddata
curl -L -o /usr/local/share/tessdata/chi_sim.traineddata \
https://github.com/tesseract-ocr/tessdata_fast/raw/main/chi_sim.traineddata
Windows用户可以自己搜一下,我没有环境,所以没办法验证。
主义把路径配置到 .env 中的这个位置。

06、接入阿里云 OCR
前面的例子大家也看到了,内置 Tesseract 虽然能提取图片PDF上的文字,但不够精确。
LiteParse 提供了一个参数,--ocr-server-url。
通过这个参数,我们可以接入外部的 OCR 服务,进一步提高识别的准确率。
这样的话,LiteParse 只负责把 PDF 渲染成图片、判断哪些页需要 OCR,精确识别这一步,把图片 POST 给指定的 HTTP 服务。
由于之前派聪明用过阿里云的Embedding,所以这次仍然选择阿里云的"通用文字识别高精版"(RecognizeAllText,Type=Advanced)。
不过由于LiteParse 期望的返回格式,和阿里云返回的格式对不上,所以我们做了一层适配。
LiteParse 的 OCR 服务规范要求返回这样的 JSON:
{
"results": [
{ "text": "识别出的一行字", "bbox": [x0, y0, x1, y1], "confidence": 0.98 }
]
}
而阿里云返回的是 SubImages → BlockInfo → BlockDetails 这种嵌套结构,每个文本块叫 BlockContent,坐标是四个角点 BlockPoints,置信度叫 BlockConfidence。
所以我在派聪明里加了一个内部适配层,专门做这个翻译。
InternalOcrController:暴露一个内部接口/api/v1/internal/ocr/liteparse,接收 LiteParse POST 过来的图片AliyunOcrService:调用阿里云 SDK,把图片丢给RecognizeAllText,拿回原始响应LiteParseOcrAdapterService:把阿里云的BlockDetails结构翻译成 LiteParse 要的results格式
我们把阿里云的OCR 做成了可插拔,如果 .env 中的 ALIYUN_OCR_ENABLED 设置为 true、填上 AccessKey,OCR 就自动从 Tesseract 切到阿里云;没有就走内置的 Tesseract。
aliyun:
ocr:
enabled: true
endpoint: ocr-api.cn-hangzhou.aliyuncs.com
access-key-id: ${ALIYUN_OCR_ACCESS_KEY_ID}
access-key-secret: ${ALIYUN_OCR_ACCESS_KEY_SECRET}
type: Advanced # 通用文字识别高精版
output-coordinate: points
callback-token: ${ALIYUN_OCR_CALLBACK_TOKEN}
接好之后,可以用 lit 命令验证了一把。
lit parse docs/paismart.pdf \
--target-pages 1 \
--dpi 300 \
--ocr-language chi_sim \
--ocr-server-url http://127.0.0.1:8081/api/v1/internal/ocr/liteparse \
--quiet
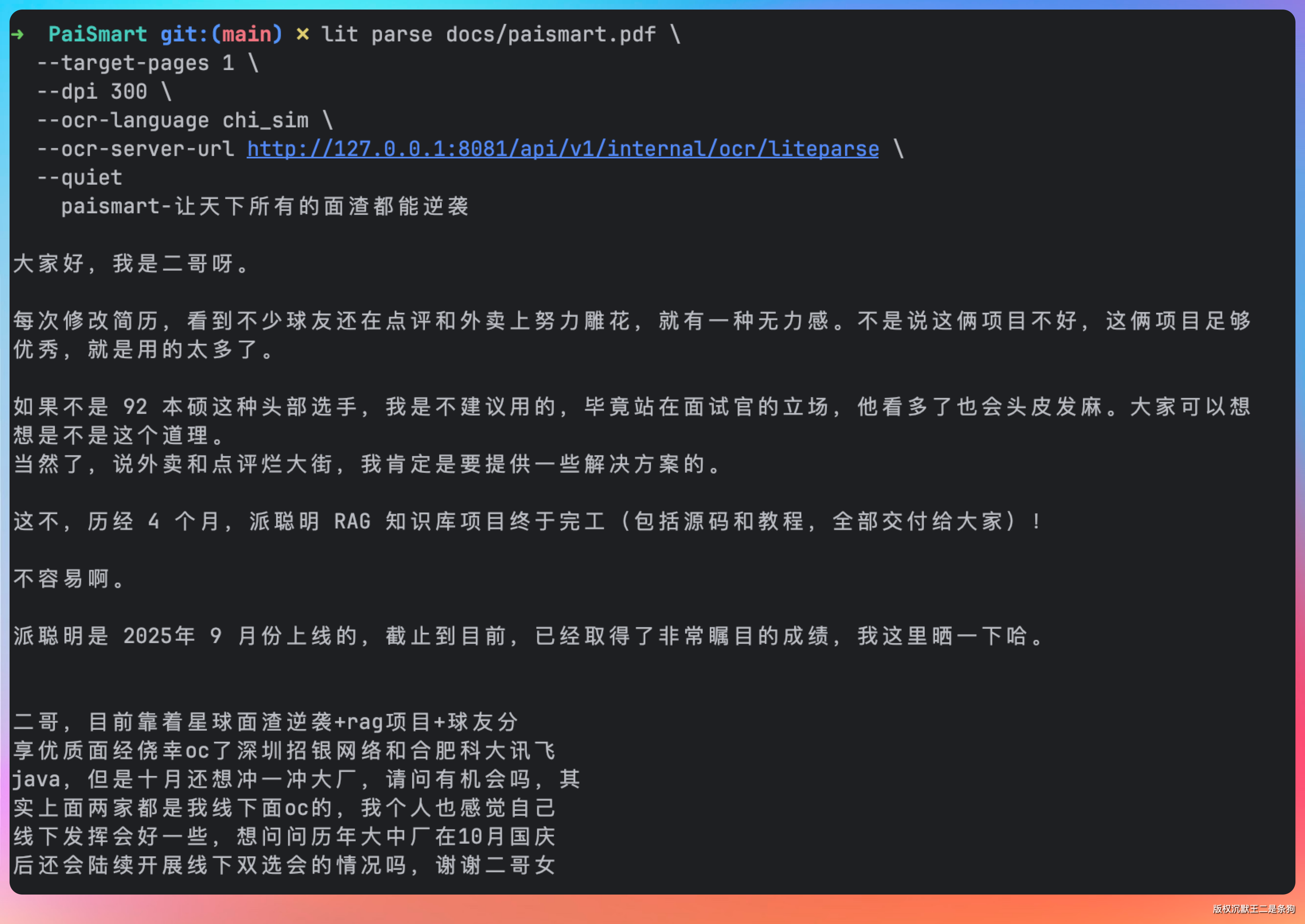
这次明显精度就提升了。
非常准确。
实际效果也非常好,图片中的内容也能够被检索到了。
07、PaiSmart如何写到简历上?
项目名称:派聪明(PaiSmart)—— 企业级开源 RAG 知识库
项目简介:面向企业内部文档的检索增强生成系统,支持文档上传、解析、向量化、语义检索与对话问答,覆盖 PDF、Office、图片等多种格式,具备组织级权限隔离与异步处理能力。
技术栈:Spring Boot、Kafka、Elasticsearch、LiteParse、Tesseract / 阿里云 OCR、HanLP。
核心职责:
- 基于 LiteParse 命令行工具重构 PDF 解析流程,通过子进程调用实现本地 OCR,解决扫描件与图片型 PDF 在知识库中无法被检索的问题
- 设计可插拔 OCR 适配层,借助 LiteParse 的 ocr-server-url 机制将识别引擎在本地 Tesseract 与阿里云高精版 OCR 之间无缝切换
- 设计页级切分策略,利用解析输出的页码信息为每个文本块标注来源页,支持检索结果溯源定位,问答可信度提升显著
- 实现父文档加子切片的语义切块方案,引入 100 字符语义重叠与 HanLP 中文分词词边界切分,提升召回
真诚点赞 诚不我欺
回复