


✅派聪明 RAG 文件上传解析面试题预测,19 道,覆盖 Kafka、MinIO、断点续传、分片上传
1.我们来聊聊文件上传的功能。当用户想要上传一个大文件(比如1GB)时,你的系统是如何接收它的?
对于大文件,派聪明采用的是‘分片上传 + 断点续传’的方式。我们会在前端先把大文件切成小的分片,比如 5MB 一块,然后并发地上传到后端。后端每收到一个分片,就存到 MinIO 中,同时会用 Redis 的 bitmap 去记录哪些分片已经上传成功。这样的好处就是,即使上传过程中断了,前端可以根据 Redis 状态判断哪些分片已经上传,不用从头开始,用户体验会比较好。
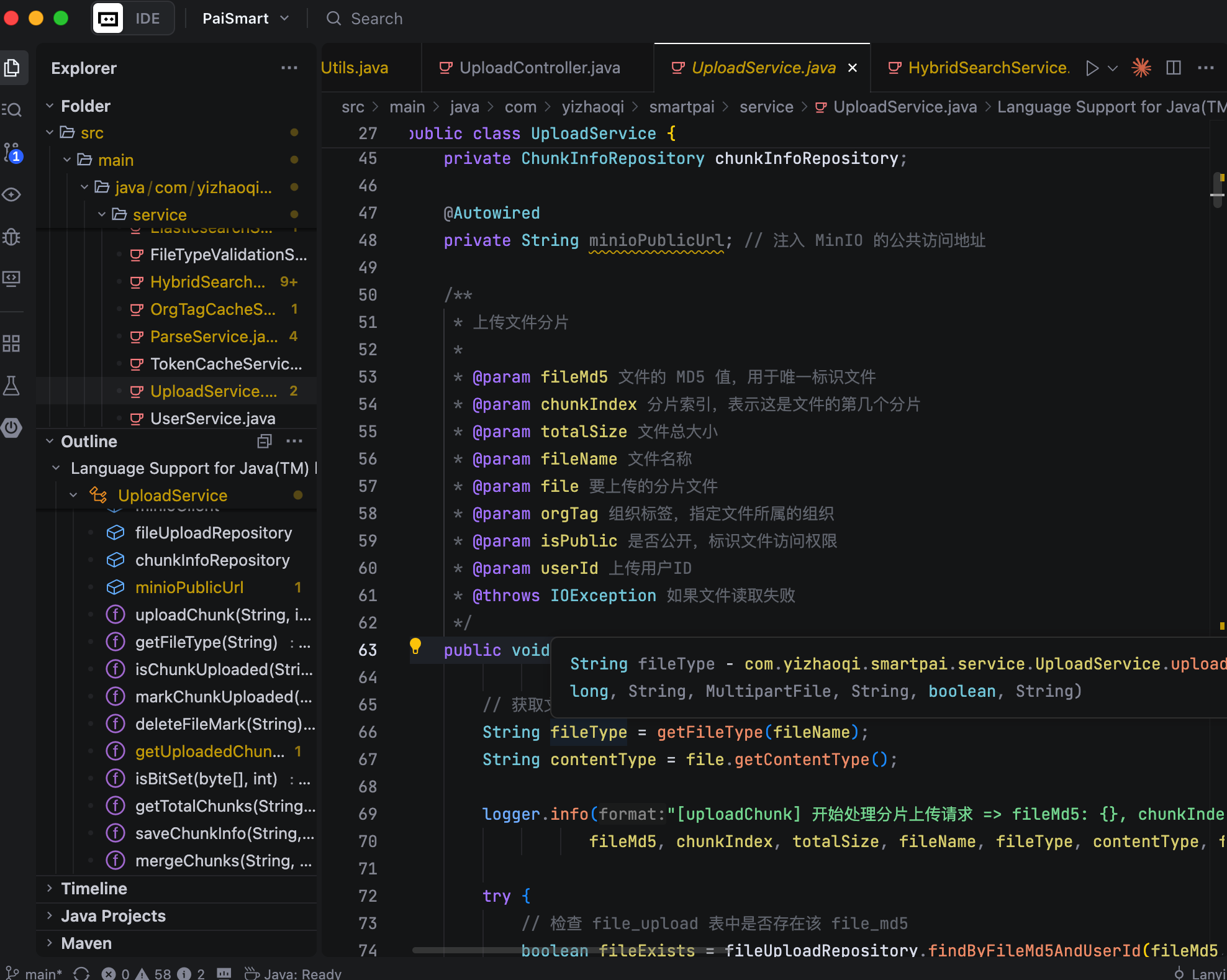
这里还有一个关键细节,就是首次上传分片时,我们会把这个文件的元信息,比如文件名、文件大小、上传者、所属组织标签等,保存到 MySQL 中,用来跟踪整个文件的上传状态。这也是为了方便后续的状态管理和权限控制。
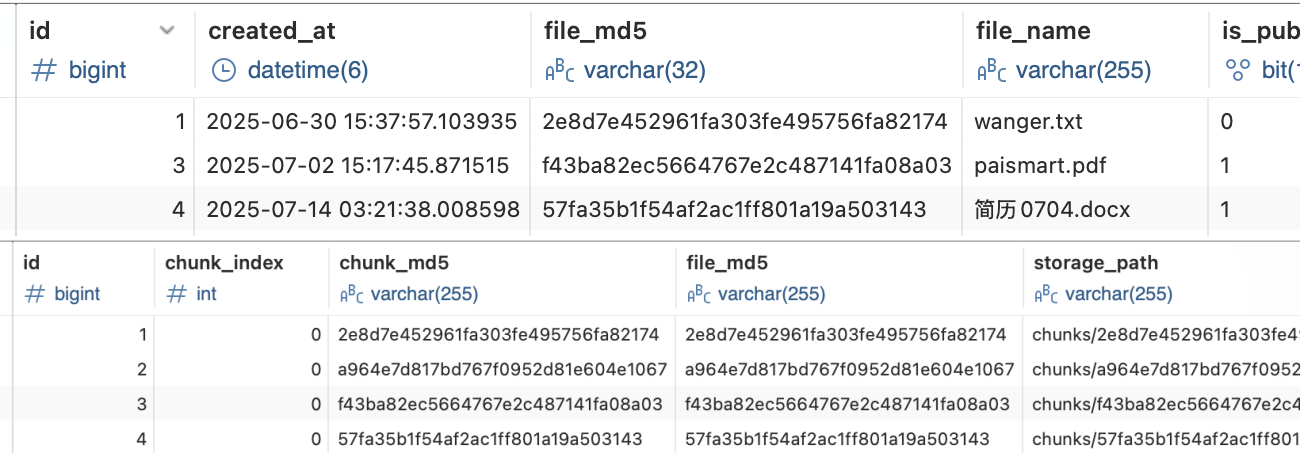
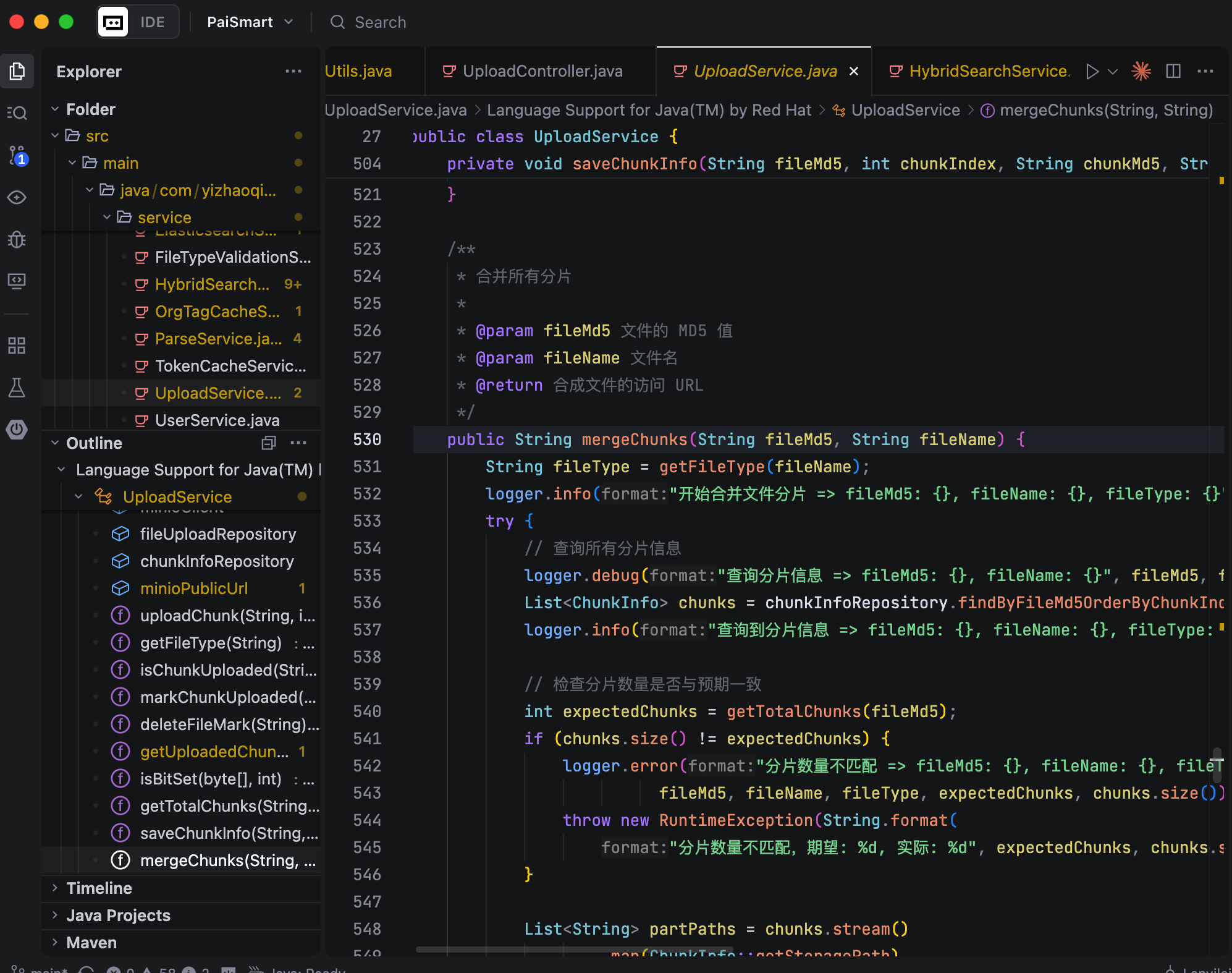
当所有分片上传完成后,前端会调用后端的合并接口。这里我们用的是 MinIO 提供的 composeObject 功能,直接在存储端完成分片的合并,完全不占用服务器的内存和 CPU 资源。合并完成后,系统会把文件状态在 MySQL 里更新为‘已完成’,并且清理掉对应的分片文件和 Redis 记录。
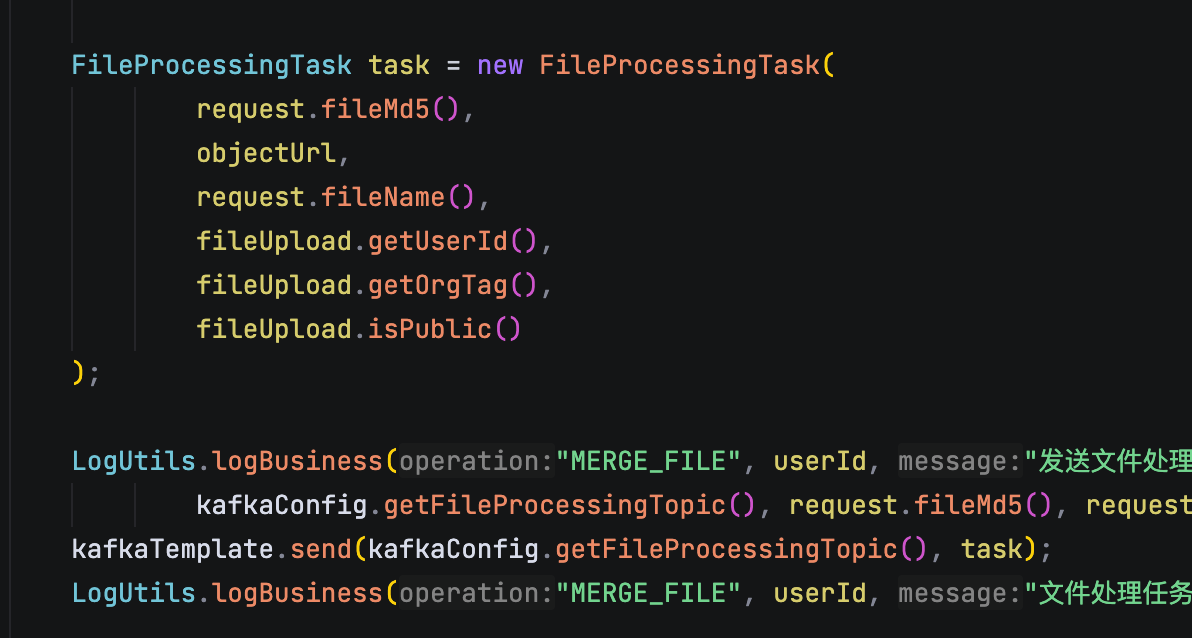
最后,文件合并后我们还会发送一条 Kafka 消息,通知后台的异步服务去做后续的文件解析、文本切片、向量化等工作,保证上传接口本身是快速响应的,不会因为后端的耗时任务拖慢用户体验。
2.分片上传...那你是如何知道哪个分片属于哪个文件的?
前端在上传文件前,会通过 MD5 算法计算出该文件内容的唯一哈希值,也就是 fileMd5,然后前端在分片上传文件时,请求不仅会包含分片本身的数据,还会附带两个关键的元信息,一...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

50人已点赞
热门评论
243 条评论
回复