


✅派聪明 RAG 文件上传解析面试题预测,19 道,覆盖 Kafka、MinIO、断点续传、分片上传
1.我们来聊聊文件上传的功能。当用户想要上传一个大文件(比如1GB)时,你的系统是如何接收它的?
对于大文件,派聪明采用的是‘分片上传 + 断点续传’的方式。我们会在前端先把大文件切成小的分片,比如 5MB 一块,然后并发地上传到后端。后端每收到一个分片,就存到 MinIO 中,同时会用 Redis 的 bitmap 去记录哪些分片已经上传成功。这样的好处就是,即使上传过程中断了,前端可以根据 Redis 状态判断哪些分片已经上传,不用从头开始,用户体验会比较好。
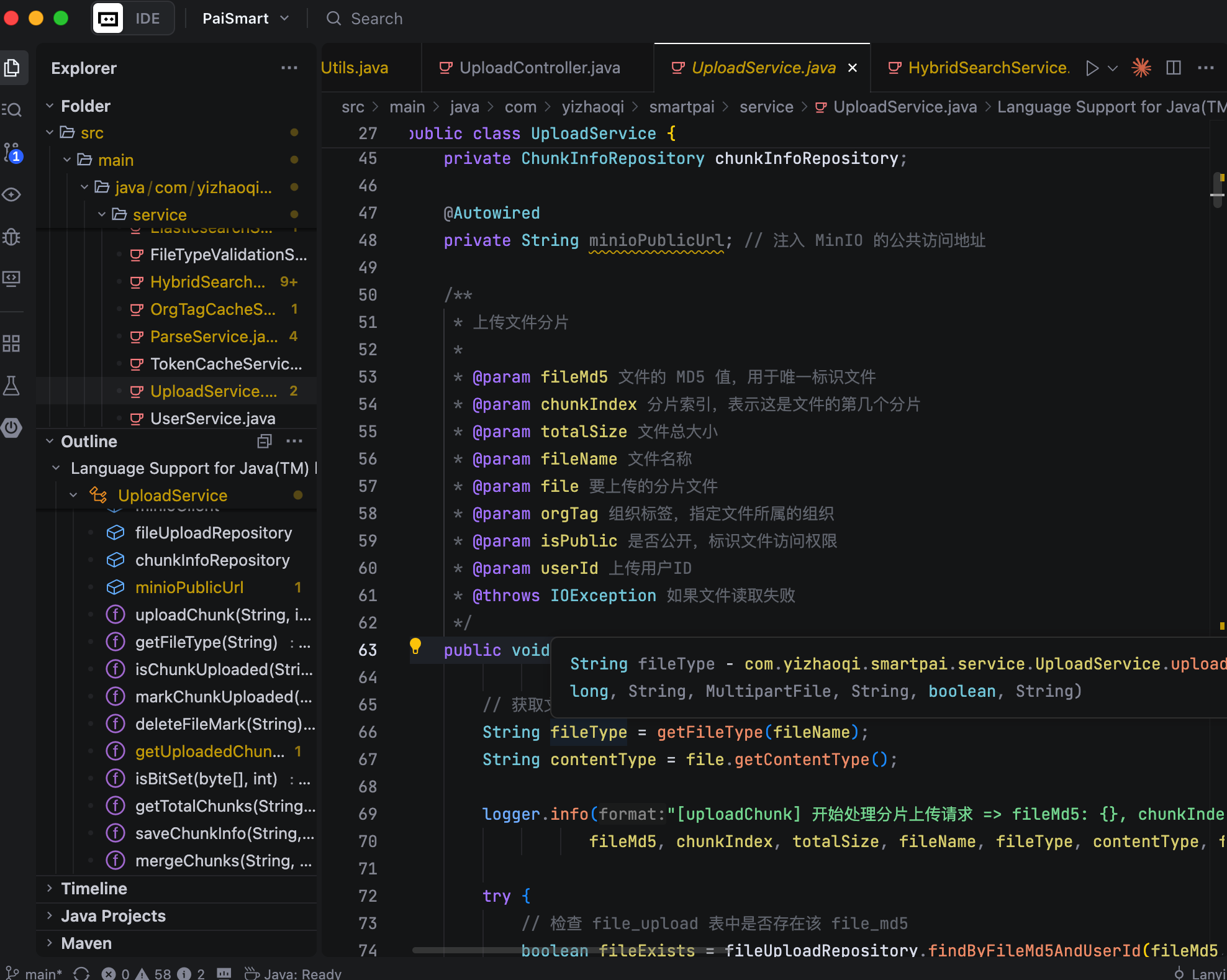
这里还有一个关键细节,就是首次上传分片时,我们会把这个文件的元信息,比如文件名、文件大小、上传者、所属组织标签等,保存到 MySQL 中,用来跟踪整个文件的上传状态。这也是为了方便后续的状态管理和权限控制。
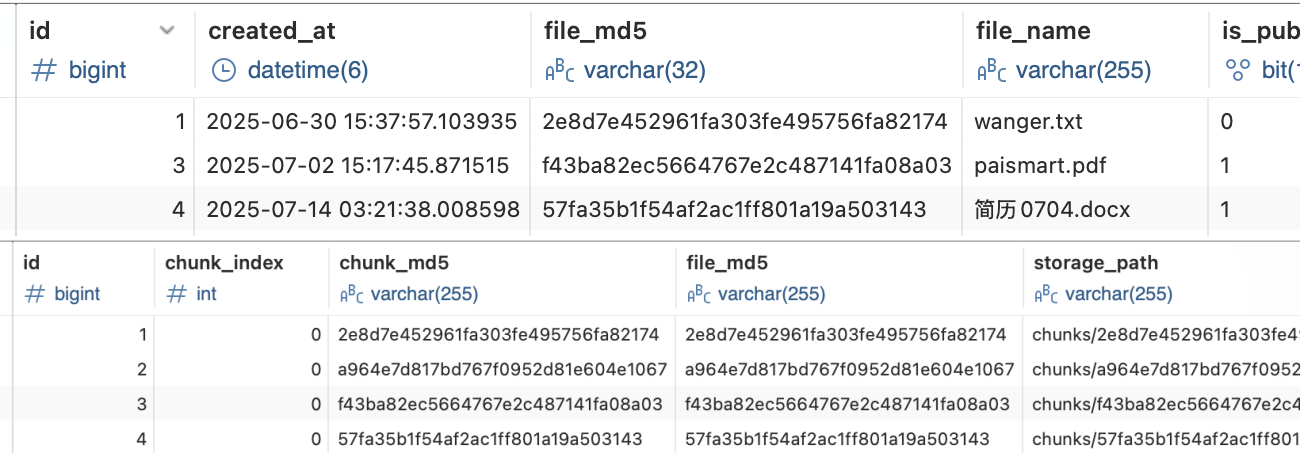
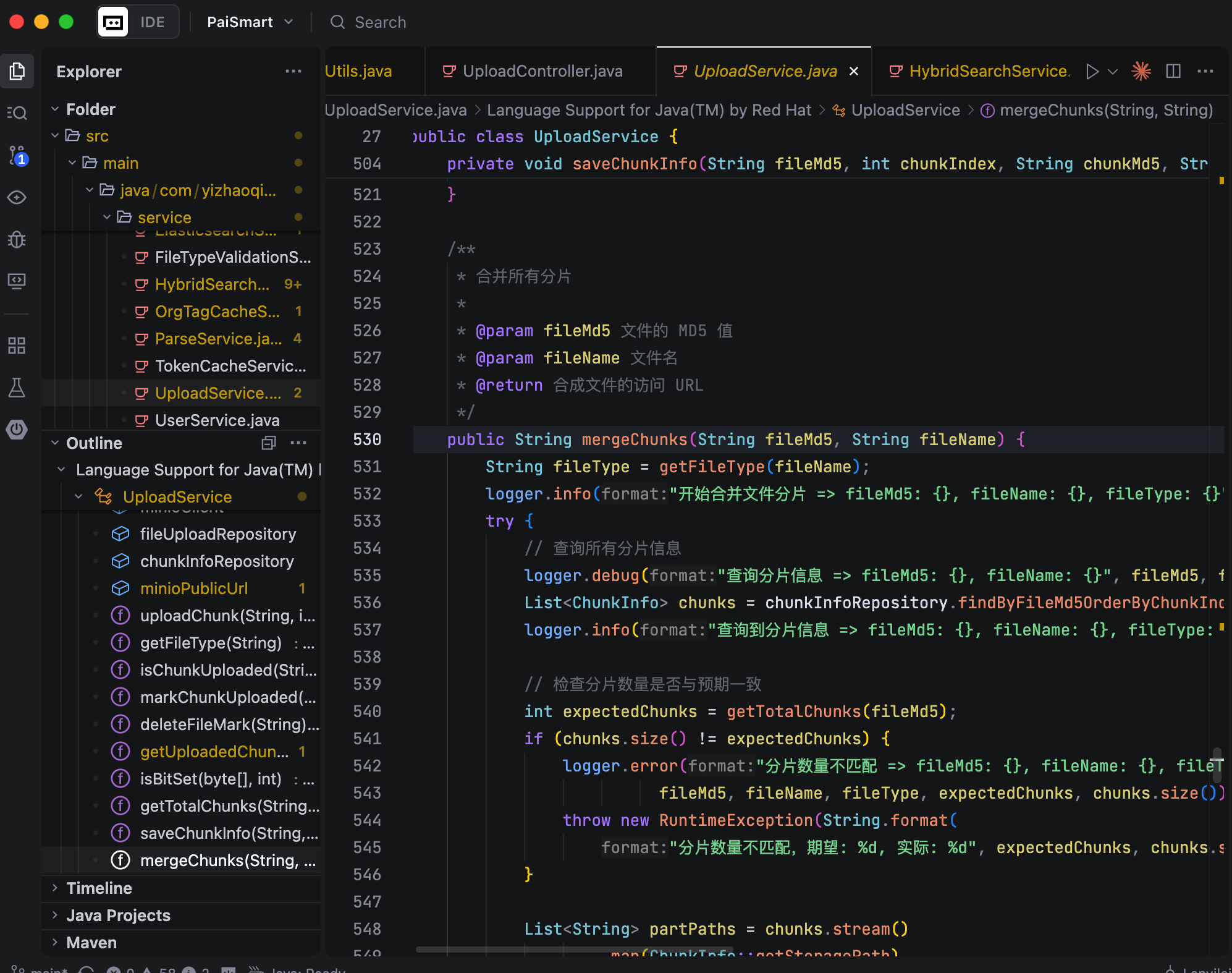
当所有分片上传完成后,前端会调用后端的合并接口。这里我们用的是 MinIO 提供的 composeObject 功能,直接在存储端完成分片的合并,完全不占用服务器的内存和 CPU 资源。合并完成后,系统会把文件状态在 MySQL 里更新为‘已完成’,并且清理掉对应的分片文件和 Redis 记录。
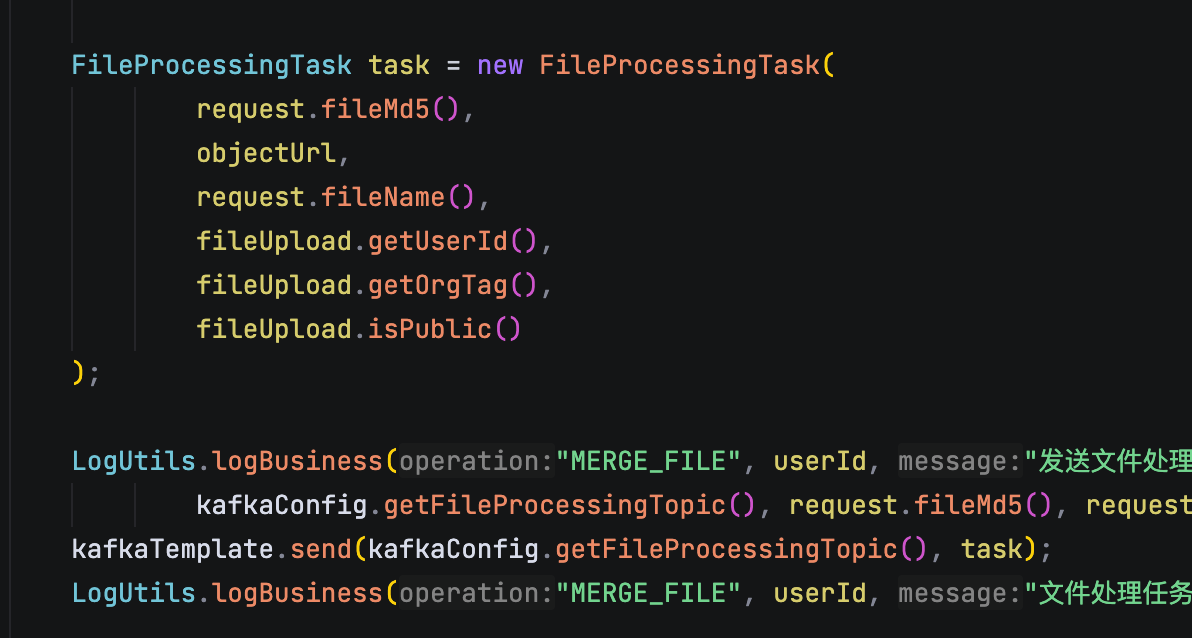
最后,文件合并后我们还会发送一条 Kafka 消息,通知后台的异步服务去做后续的文件解析、文本切片、向量化等工作,保证上传接口本身是快速响应的,不会因为后端的耗时任务拖慢用户体验。
2.分片上传...那你是如何知道哪个分片属于哪个文件的?
前端在上传文件前,会通过 MD5 算法计算出该文件内容的唯一哈希值,也就是 fileMd5,然后前端在分片上传文件时,请求不仅会包含分片本身的数据,还会附带两个关键的元信息,一个是 fileMd5,一个是 chunkIndex,用于记录当前分片在原始文件中的顺序。
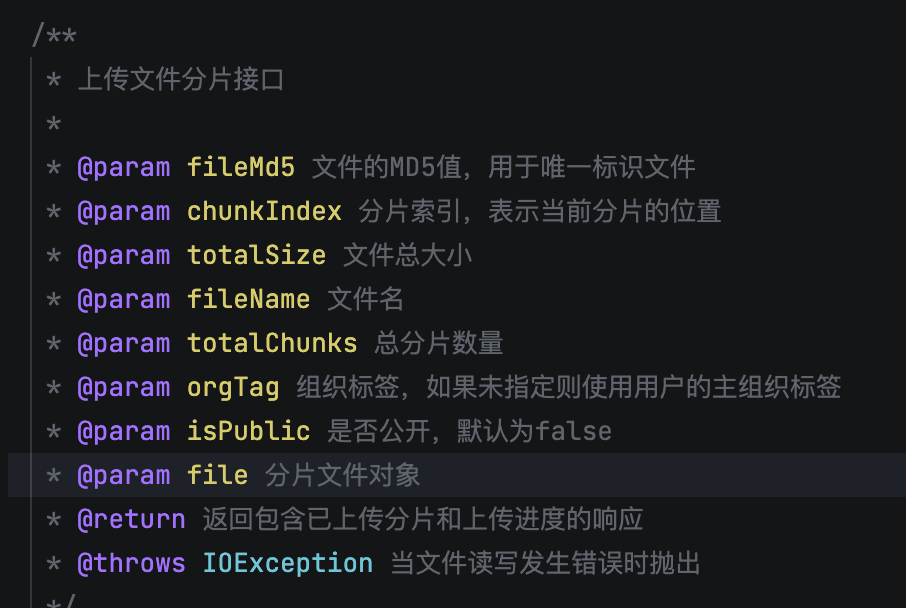
后端接收到分片后,除了存储分片本身之外,还会根据这个 fileMd5 和 chunkIndex 把分片放到对应的位置上。比如我们会在 MinIO 里以 chunks/{fileMd5}/{chunkIndex} 这样的结构来存储,确保所有分片归属于正确的文件,同时用 Redis 去记录每个分片的上传状态。
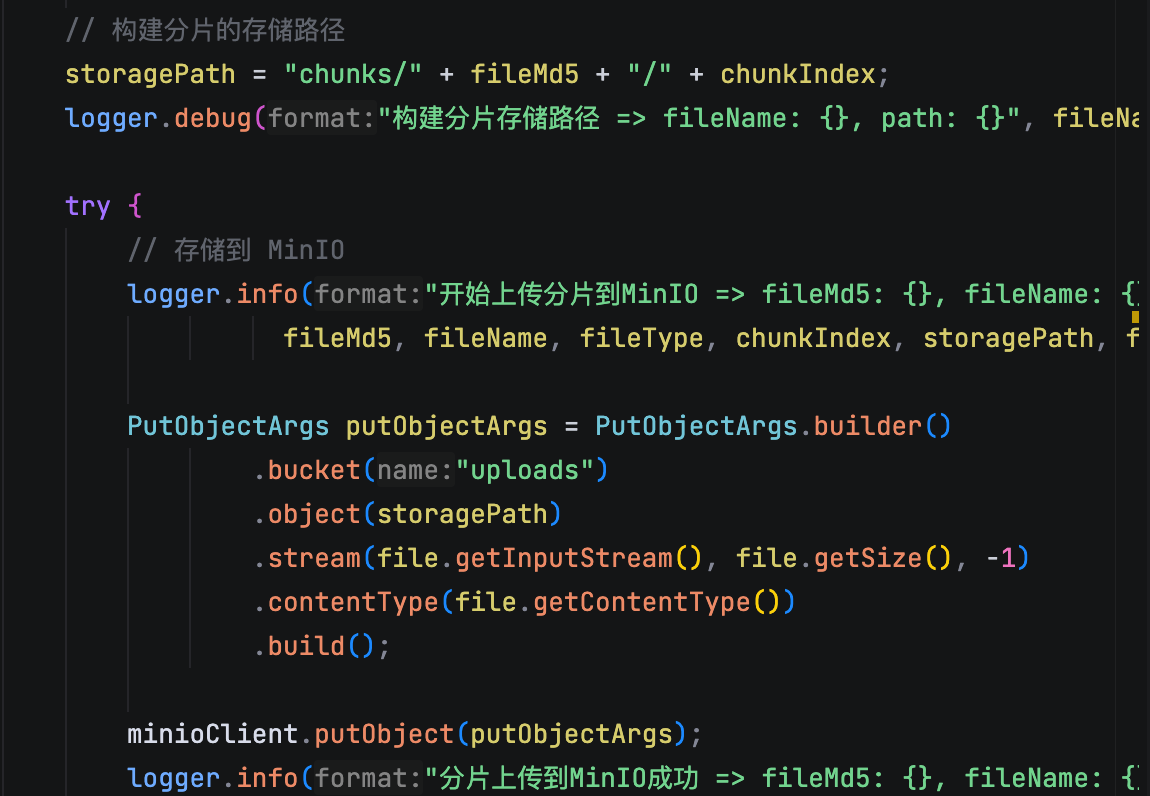
等前端把所有分片都传完了,后端再根据这个 fileMd5 把所有分片拿出来,按 chunkIndex 顺序拼接在一起,通过 MinIO 的 composeObject 方法直接在存储端完成合并,效率非常高。

3.如果上传中网络断了,如何实现‘断点续传’?
后端在收到每个分片之后,一方面会把分片存储到 MinIO,另一方面也会用 Redis 的 bitmap 去记录这个分片的上传状态。这样后端就能实时知道这个文件的哪些分片上传成功了,哪些还没传。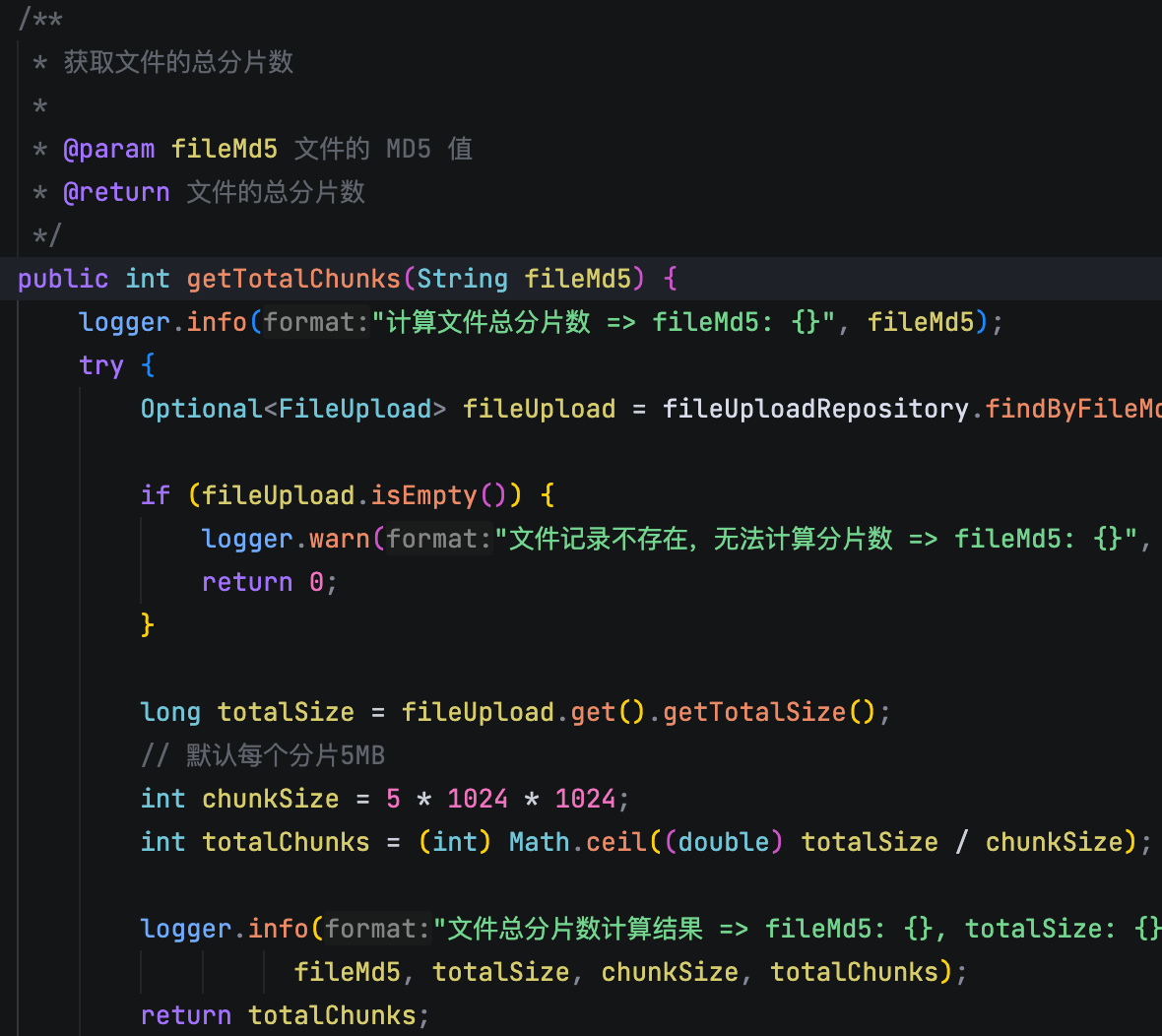
等到网络恢复后,前端会带着这个文件的 MD5 去后端的 Redis 里查所有分片的状态,前端拿到分片状态后,在重新上传的时候,就会跳过那些已经上传成功的分片,只上传那些还没传的。这样就避免了重复上传。
当然了,后端在重新上传的时候,也会进行核验。
4.你用什么来存储这个临时的分片上传状态?数据库还是缓存?为什么?
我是用 Redis 来管理分片上传的临时状态的。因为分片上传属于高频写入,比如一个 1GB 的大文件可能会被切割成上百个甚至上千个分片,每上传一个分片,后端都要记录一下“这个分片的状态”。如果是用 MySQL 的话,MySQL 的压力会特别大,而且这些数据都是临时的,合并完之后就没用了,不值得进库。
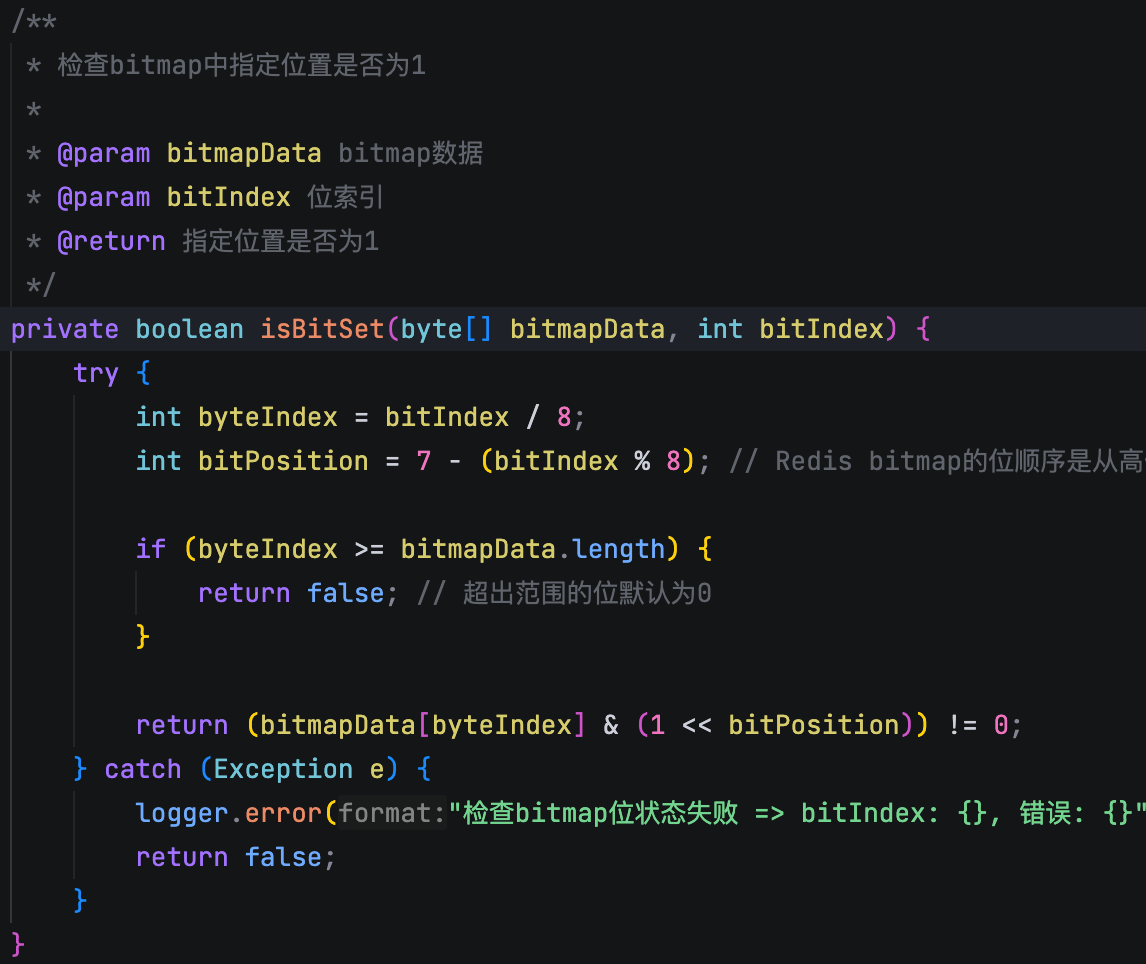
Redis 刚好适合这种场景。它是内存型的键值对存储,读写速度特别快,而且我们用的是 Redis 的 Bitmap。简单来说,我们会用文件的 MD5 作为 Redis 的 key,然后用一串“0”和“1”的位图来记录每个分片的状态,比如第 0 个位代表第 0 个分片,第 1 个位代表第 1 个分片……上传一个分片就把对应的 bit 位标记为 1。
这样记录状态特别省内存,例如,要跟踪一个 100 万个分片的文件,只需要大约 122KB 的内存(1,000,000 bits / 8 / 1024 ≈ 122 KB),而且查询和更新都很快,基本就是 O(1) 的时间复杂度。
5.这些上传的临时分片,存在哪?
存在 MinIO 里。因为分片上传场景下,文件往往比较大,而且一旦上传中断或者失败,之前已经上传的分片是需要持久化的。
MinIO 还是一个遵循 S3 协议的对象存储系统,天然适合这种大文件、多分片的场景,而且支持高并发读写,性能也不错。
并且所有分片上传成功后,还需要一个合并操作,MinIO 恰好就提供了这么一个 API——composeObject。
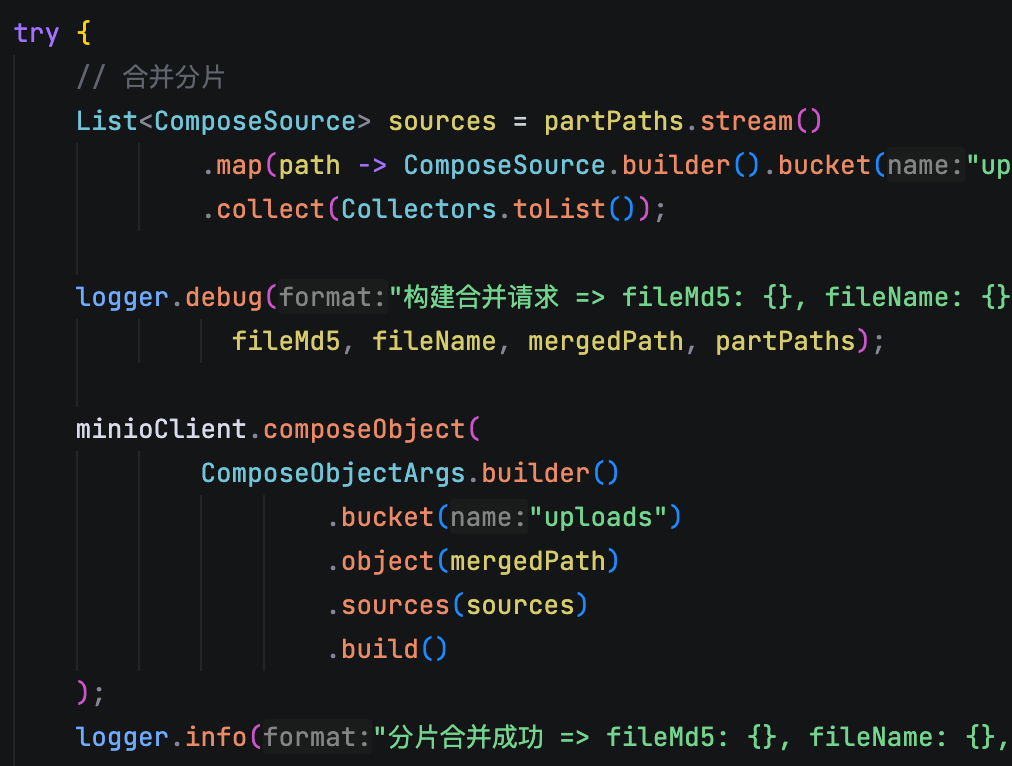
6.详细描述分片上传与断点续传的实现机制。在这个过程中,Redis和MinIO分别承担了什么核心角色?
我先说分片上传,每个分片在上传成功之后,后端是直接把它存在 MinIO 里的。等所有分片都上传完成后,我们会调用 MinIO 的 compose 接口,在服务端把这些分片直接拼成一个完整的文件。
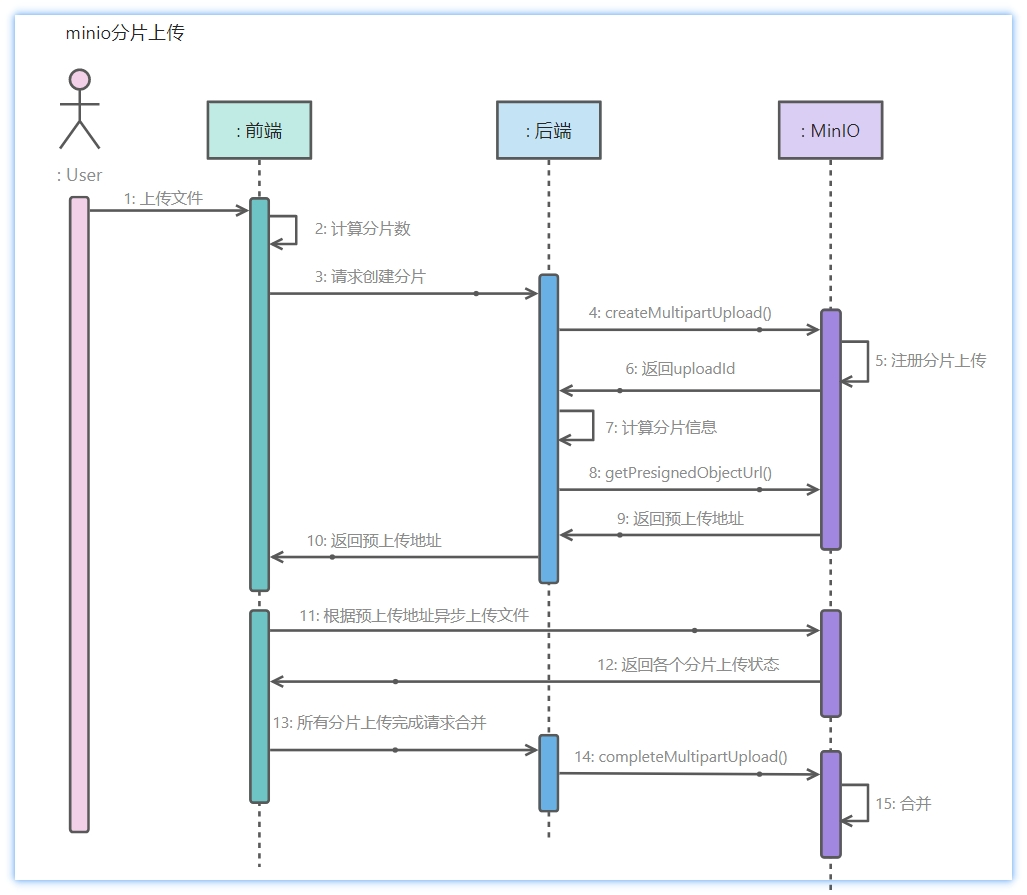
再说一下断点续传。
光有 MinIO 还不够,因为我们还需要知道当前这个文件上传到第几块了,哪些分片已经传过了。所以在上传的过程中,每当一个分片上传成功,后端会在 Redis 里记录这个分片的上传状态。
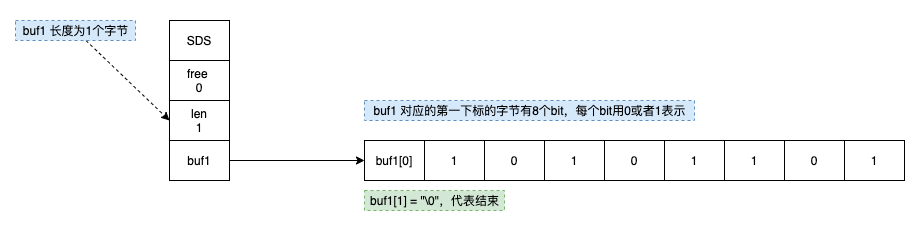
具体实现上,我们是用 Redis 的 Bitmap 来做的,把文件的 MD5 值作为 Redis 的 Key,每个分片对应 Bitmap 里的一个 bit 位,上传成功就把那个 bit 设置成 1。
这样后端只需要再给前端提供一个查询分片状态的接口:告诉前端哪些分片已经上传了,哪些还没上传,这样前端就可以进行断点续传了。后端也会在合并前做一个完整性校验,看是否所有分片都到齐了。
总结来说,MinIO 主要负责存实际的分片数据和最终的完整文件,Redis 主要负责存上传过程中的状态。
7.如何处理上传过程中的各种异常情况?例如,如果用户的网络突然中断,或者某个分片上传失败了,你设计了什么样的恢复机制?
假如说用户的网络...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

51人已点赞
热门评论
256 条评论
回复