


✅派聪明 RAG 知识库检索面试题预测,覆盖 ElasticSearch 的 KNN 和 BM25
1.当一个用户在搜索框里输入一句话然后点击搜索,系统大致会经历一个怎样的处理流程?
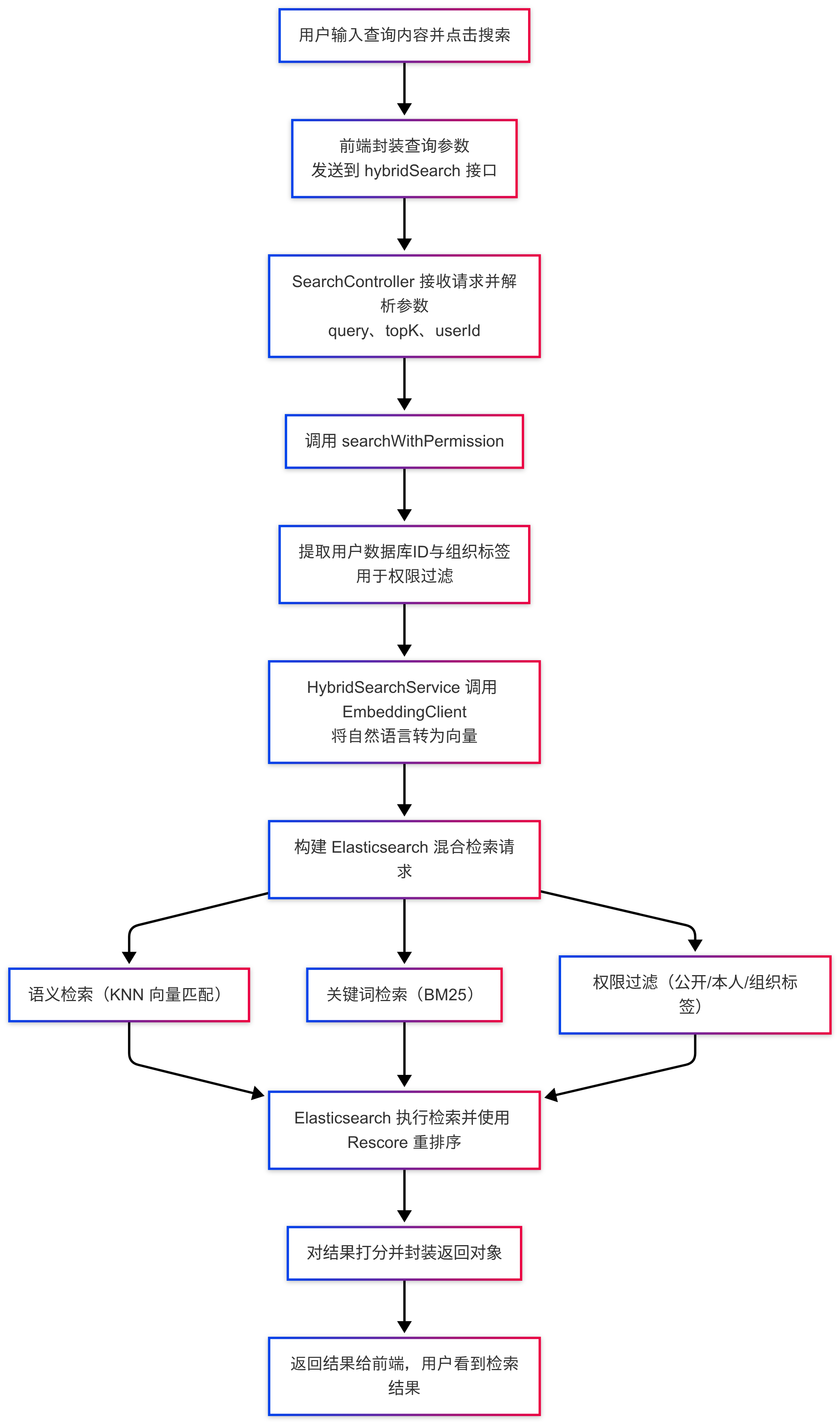
首先,用户通过前端页面输入搜索内容并提交,前端会将查询语句、用户信息等参数封装成 HTTP 请求发送到后端。后端接收到请求后,会解析出查询关键词和用户身份。
在进入搜索逻辑前,系统首先会调用外部的 Embedding 模型将用户的自然语言查询转化为向量表示。这一步是实现语义相似度搜索的基础。同时,系统还会提取出用户对应的组织标签,用于后续的权限过滤。
随后,系统会构造出一个 Elasticsearch 混合查询。融合了三类能力:首先是基于查询向量的 KNN 语义检索,用于找出语义上最接近的文本块;其次是基于关键词的 BM25 检索,用于匹配关键词相似的文档;最后是权限过滤机制,确保返回的文档必须是公开的、或属于该用户本人,或其组织标签在用户的有效标签列表中。
为了提高结果的相关性和精度,我们还会使用 Elasticsearch 的 rescore 机制,根据 BM25 与向量匹配的得分对初步召回的结果进行重排序,找到最终排名靠前的文档,并打分后返回给前端。
- 什么是 KNN?https://www.elastic.co/cn/what-is/knn
- 什么是 BM25:https://www.elastic.co/cn/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables
备注:
kNN 又称 k 最近邻算法,会使用临近度来将一个数据点与训练时所使用并已记住的一个数据集进行对比,从而做出预测。其中字母 k 表示在分类...

35人已点赞










热门评论
81 条评论
回复