


✅如何基于Spring Security实现派聪明 RAG 知识库的RBAC 权限系统?
RBAC,全称为 Role-Based Access Control,翻译过来叫基于角色的访问控制,通过将用户分配到不同的角色,并为角色分配权限,从而实现对资源的访问控制。
那如何实现 RBAC 呢?派聪明用的是 Spring Security。Spring Security 本质上是一个基于 Filter 的安全框架。当请求进入应用时,会经过一系列安全过滤器链,每个过滤器负责不同的安全功能,比如认证、授权、CSRF 防护等。
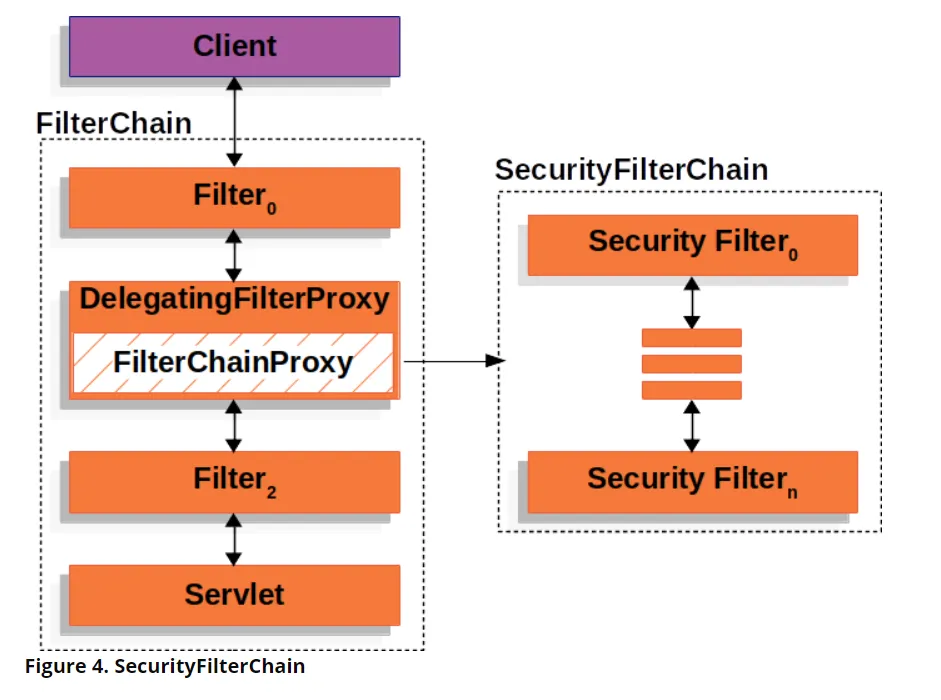
Spring Security 主要解决了两大核心问题:认证(Authentication)和授权(Authorization)。认证就是验证“你是谁”,比如用户登录时验证用户名密码是否正确;授权就是验证“你能做什么”,比如检查用户是否有权限访问某个页面或调用某个接口。
本篇教程将详细介绍如何基于 Spring Security 实现 RBAC,包括用户注册、登录、JWT 认证、请求拦截与授权等核心流程。
一、RBAC 的核心概念
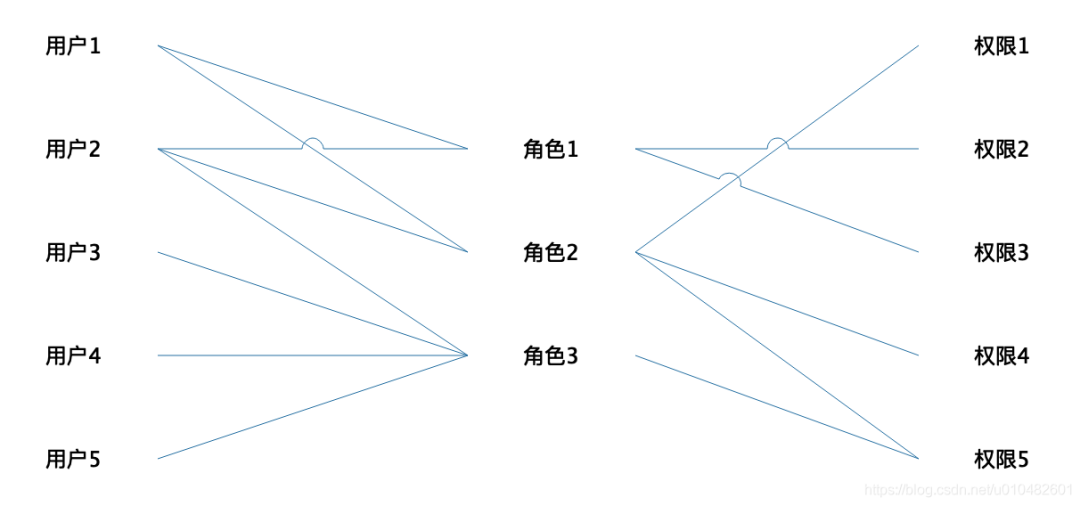
RBAC 的核心思想是给用户赋予某些角色,而每个角色拥有某些权限。等于说,一个权限可以分配给多个角色,一个角色可以拥有多个权限,同样一个用户可以分配多个角色,一个角色也可以对应多个用户,对应模型如下所示:

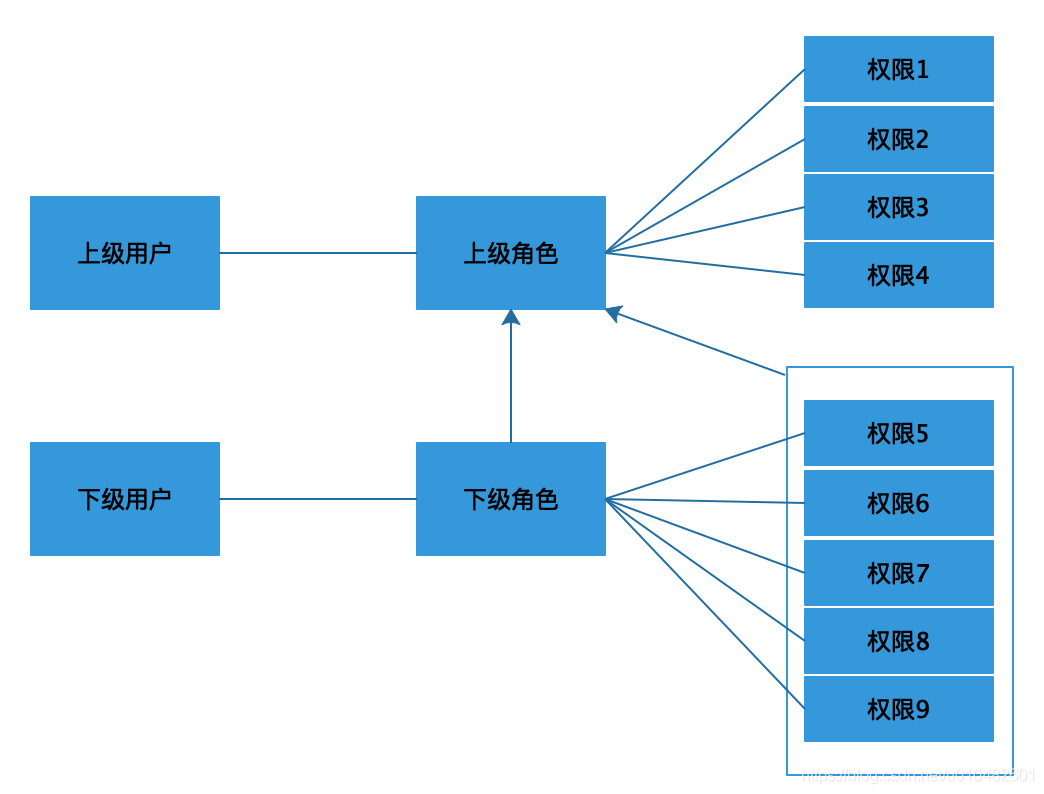
对于派聪明来说,每个公司都有自己的组织架构,比如公司里管理知识库的人员有王老板和毕小三等,王老板不仅拥有毕小三的权限,也拥有李四眼的权限,像这种管理关系向下兼容的模式就需要用到角色继承的 RBAC 模型。角色继承的 RBAC 模型的思路是上层角色继承下层角色的所有权限,并且可以额外拥有其他权限。
在派聪明系统中,Spring Security 的 RBAC 实现分为几个层次:
①、基础角色的定义:
- USER(普通用户) :可以上传文件、进行对话、查看自己的历史记录
- ADMIN(管理员) :除了普通用户的所有权限外,还能管理所有用户、查看系统状态、管理知识库
②、URL 级别的权限控制:
// 任何人都能访问的接口(如登录、注册)
.requestMatchers("/api/v1/users/register", "/api/v1/users/login").permitAll()
// 普通用户和管理员都能访问的接口
.requestMatchers("/api/v1/upload/**").hasAnyRole("USER", "ADMIN")
// 只有管理员能访问的接口
.requestMatchers("/api/v1/admin/**").hasRole("ADMIN")
③、组织标签权限控制:
- 私人空间 :以"PRIVATE_"开头的资源,只有创建者能访问
- 组织资源 :根据用户的组织标签来控制访问权限
- 公开资源 :所有认证用户都能访问
二、派聪明中权限控制的代码结构
派聪明的 Spring Security RBAC 实现采用了非常清晰的分层架构设计,每个层次都有明确的职责分工。
src/
├── main/
│ ├── java/com/yizhaoqi/smartpai/
│ │ ├── config/ # 配置类
│ │ │ ├── SecurityConfig.java
│ │ │ ├── JwtAuthenticationFilter.java
│ │ ├── controller/ # 控制器
│ │ │ ├── UserController.java
│ │ ├── service/ # 服务层
│ │ │ ├── UserService.java
│ │ │ ├── CustomUserDetailsService.java
│ │ ├── repository/ # 数据访问层
│ │ │ ├── UserRepository.java
│ │ ├── model/ # 数据模型
│ │ │ ├── User.java
│ │ ├── utils/ # 工具类
│ │ │ ├── PasswordUtil.java
│ │ │ ├── JwtUtils.java
│ ├── resources/
│ ├── application.yml # 配置文件
└── test/
├── java/com/yizhaoqi/smartpai/
├── service/ # 测试类
├── UserServiceTest.java
配置层(config)是整个安全框架的"大脑",负责制定游戏规则。SecurityConfig.java 相当于安全系统的总指挥,定义了哪些 URL 需要什么权限,配置过滤器链的执行顺序。JwtAuthenticationFilter.java 则像门卫一样,检查每个请求的shenfenzheng(JWT 令牌)是否有效。
控制器层(controller)是用户请求的第一站,负责接收和响应。UserController.java 处理用户相关的所有操作,如登录、注册、获取用户信息等,是用户与系统交互的入口。
服务层(service)是业务逻辑的核心,负责具体的业务处理。UserService.java 处理用户相关的业务逻辑,比如用户注册时的数据验证、密码加密等。CustomUserDetailsService.java 专门为 Spring Security 服务,负责从数据库加载用户信息并转换成 Spring Security 能理解的格式。
数据访问层(repository)是与数据库打交道的地方。UserRepository.java 定义了如何从数据库中查询用户信息,使用 Spring Data JPA 简化数据库操作。
数据模型层(model)是数据的"蓝图"。User.java 定义了用户实体的结构,包括用户名、密码、角色、组织标签等字段。
工具类层(utils)是系统的"工具箱"。PasswordUtil.java 负责密码的加密和验证,确保密码安全。JwtUtils.java 负责 JWT 令牌的生成、解析和验证,是无状态认证的核心。
配置文件(resources)中的 application.yml 是系统的配置中心,包含数据库连接、JWT 密钥、Redis 配置等重要参数。
测试层(test)中的 UserServiceTest.java 确保业务逻辑的正确性,通过单元测试验证各个功能模块。
三、派聪明中权限控制的核心代码实现
01、用户模型类
User 实体类是派聪明系统实现 RBAC 权限控制的数据基础,通过 JPA 注解实现完整的用户信息管理。 @Entity 和 @Table 注解将其映射到数据库的"users"表,并通过 @UniqueConstraint(columnNames = "username")在数据库层面确保用户名的唯一性,防止重复注册。
@Data
@Entity
@Table(name = "users", uniqueConstraints = @UniqueConstraint(columnNames = "username"))
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String username;
@Column(nullable = false)
private String password;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private Role role;
@Cre...企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

21人已点赞
热门评论
21 条评论
回复