


美团大模型应用开发面经,主要是RAG这块
继续给大家分享美团大模型应用开发的面经,及详细答案,系好安全带,我们粗粗粗发~~
content
01、Embedding 向量检索的原理是什么?如何保证检索准确性?
“先说说你们项目里 Embedding 向量检索是怎么做的?”老王扶了扶快从鼻梁上掉下来的眼镜,开始拷打我派聪明 RAG 项目了。
我说:“我们用的是阿里的 text-embedding-v4 模型,把文本转成 2048 维的向量,存到 Elasticsearch 里。检索的时候,用户的问题也会先过一遍 Embedding 模型,变成同维度的向量,然后用 ES 的 KNN 做近邻搜索。”
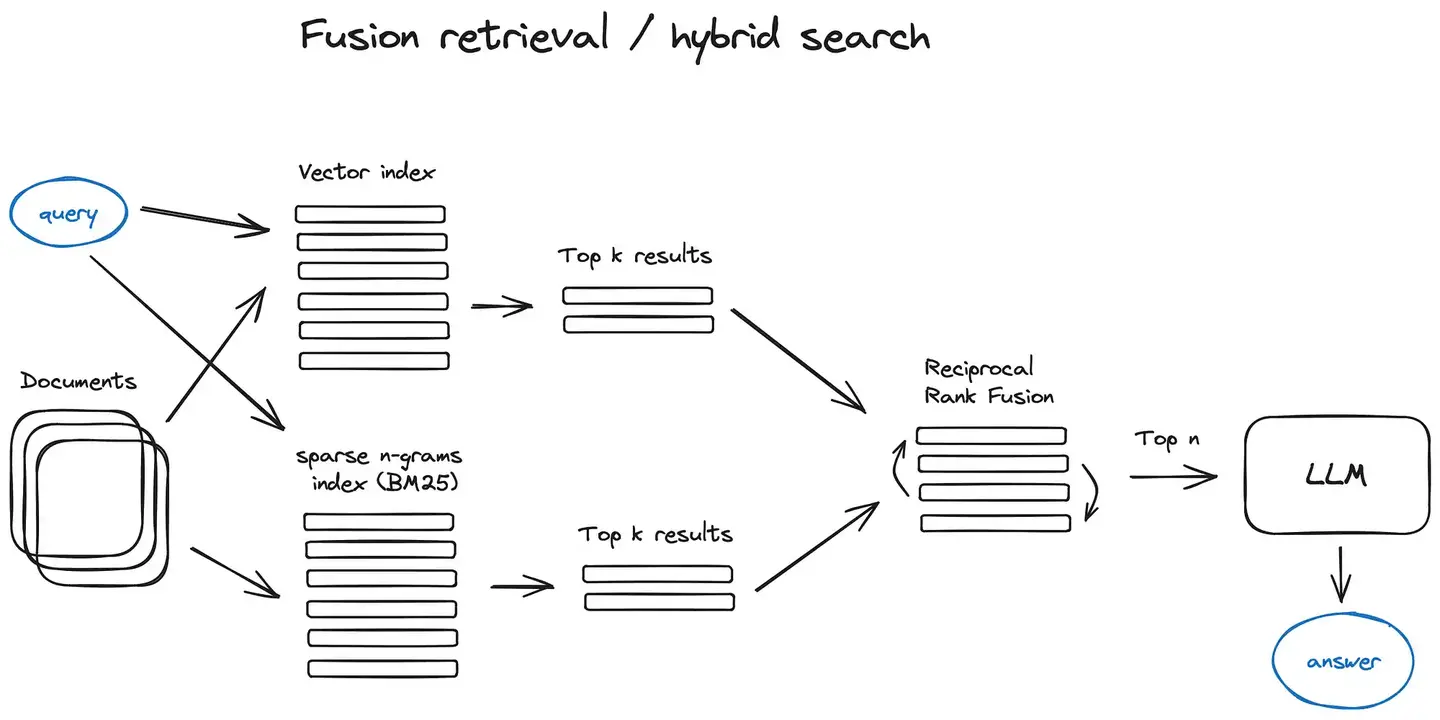
向量检索的原理是什么?
Embedding 模型干的事情,就是把一段文字映射到一个高维空间的点上。语义相近的文本,在这个空间里距离就近。比如“Java 的垃圾回收机制”和“JVM GC 原理”,虽然字面完全不一样,但 Embedding 之后的向量距离会非常近。
检索的时候就是在这个高维空间里找“最近的邻居”——K-Nearest Neighbors,简称 KNN。ES 8.x 原生就支持这个能力,不需要装额外的插件。
“那光靠向量检索能保证准确吗?”老王追问。
我说:“光靠向量检索肯定不够,所以我们做了混合检索。”
在 HybridSearchService 里,我们设计了一个两阶段检索策略:
第一阶段:KNN 向量召回 + 关键词必中。 先用 KNN 做大范围召回,召回窗口是 topK 的 30 倍。同时加一个 must match 条件,要求文档必须包含用户查询的关键词。这一步是“宁可多召,不能漏掉”。
// ...
真诚点赞 诚不我欺
回复