


面试结束后,我反问:“就面个实习至于上这么大强度吗?”面试官:“你对 RAG、Agent、MCP、Skill 理解得很到位,所以要求高一点。”
滴滴一面,派聪明RAG面经

但讲老实话,这次面试确实顶,顶到肺了快。😄
兄弟姐妹们可以先看看这些题目,真的,不是一般人,扛不住啊。
系好安全带,咱们粗粗粗粗发~~
content
01、RAG 项目,你里边的分片是怎么设计的?然后还有就是内容的解析以及向量化又是怎么做的,然后在检索召回的时候又是怎么做的?
我说:「我分四块儿来讲,分片、解析、向量化、召回。」
老王点点头,往椅子上一靠,看样子是准备听我的长篇大论了。
分片这一块,派聪明用的是多层级语义分片,按段落 → 句子 → 词 → 字符这种递进的方式来切。分片大小默认设的是 512 字节,没有用 overlap。
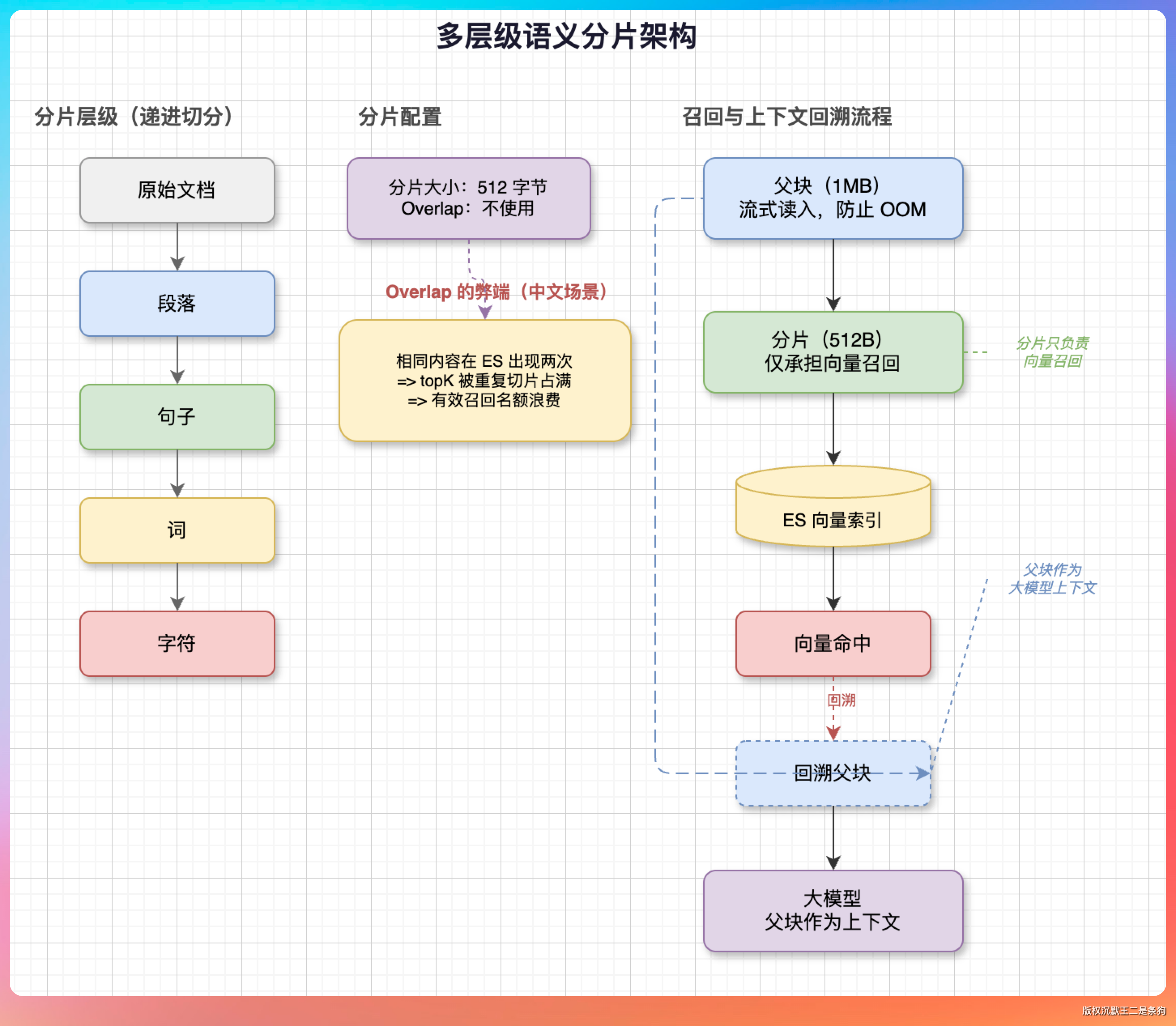
老王这时候插了一句:「不用 overlap 不怕语义割裂吗?」
我说:「这个问题我们也想过。后来发现 overlap 在中文场景下效果一般,反而会让相同内容在 ES 里出现两次,召回的时候排在前面的几条都是同一段落的不同切片,相当于浪费 topK 名额。我们的做法是,分片之外维护一个 1MB 的父块,流式读进来防止 OOM,分片只承担向量召回,命中之后回溯到父块给大模型作为上下文。」
老王眼睛亮了一下,没说话,示意我继续。
解析这一块,用的是 Apache Tika 2.9.1,自动识别格式,支持 PDF、Word、Excel、PPT、Markdown、HTML 这几大类。PDF 我们是用 PDFBox 单独处理的,按页码切片,同时把页眉页脚这些重复出现的字符给剔除掉。中文长句切词用的 HanLP 的 StandardTokenizer。
向量化走的是阿里千问的 text-embedding-v4...

真诚点赞 诚不我欺
回复