


✅派聪明 RAG 聊天助手面试题预测,针对 WebSocket 和 prompt
1.我们来聊聊这个聊天助手。它最吸引人的特点之一就是像真人聊天一样,答案一个字一个字地蹦出来。这种‘流式响应’或‘打字机效果’,在技术上是如何实现的?
我先从整体的流程说起:当前端用户开始一次对话时,浏览器会通过 WebSocket 与后端建立一个长连接。这是一种双向的、长时间保持的连接,非常适合实时交互的场景,比如流式响应、打字机效果。
一旦用户在前端发出提问,这个消息就会通过 WebSocket 通道发送到后端。后端接收到消息后会去调用知识库去做一次混合检索,找出相关的文本内容后,再拼接上用户的历史上下文,构建一个完整的 Prompt。
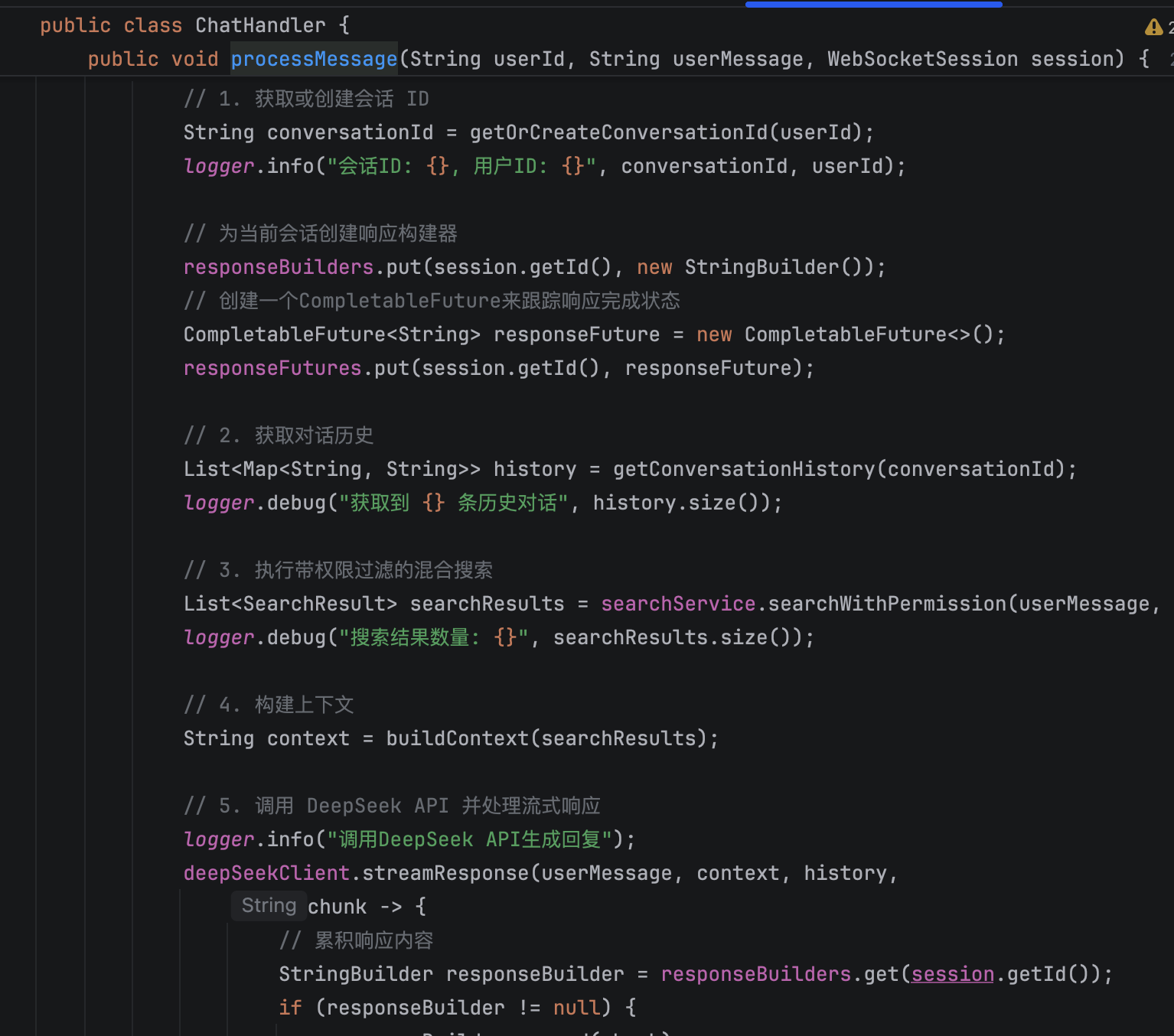
接着去调用 DeepSeek,我们调用的是流式响应的 API。这一步是实现打字机效果的关键:我们用 Spring WebFlux 的 WebClient 作为 HTTP 客户端,在请求 LLM 的时候也以流式的方式订阅返回的数据流。也就是说,LLM 一边生成内容,一边把内容分成一小段一小段地推给我们,我们这边就一边接收一边处理。
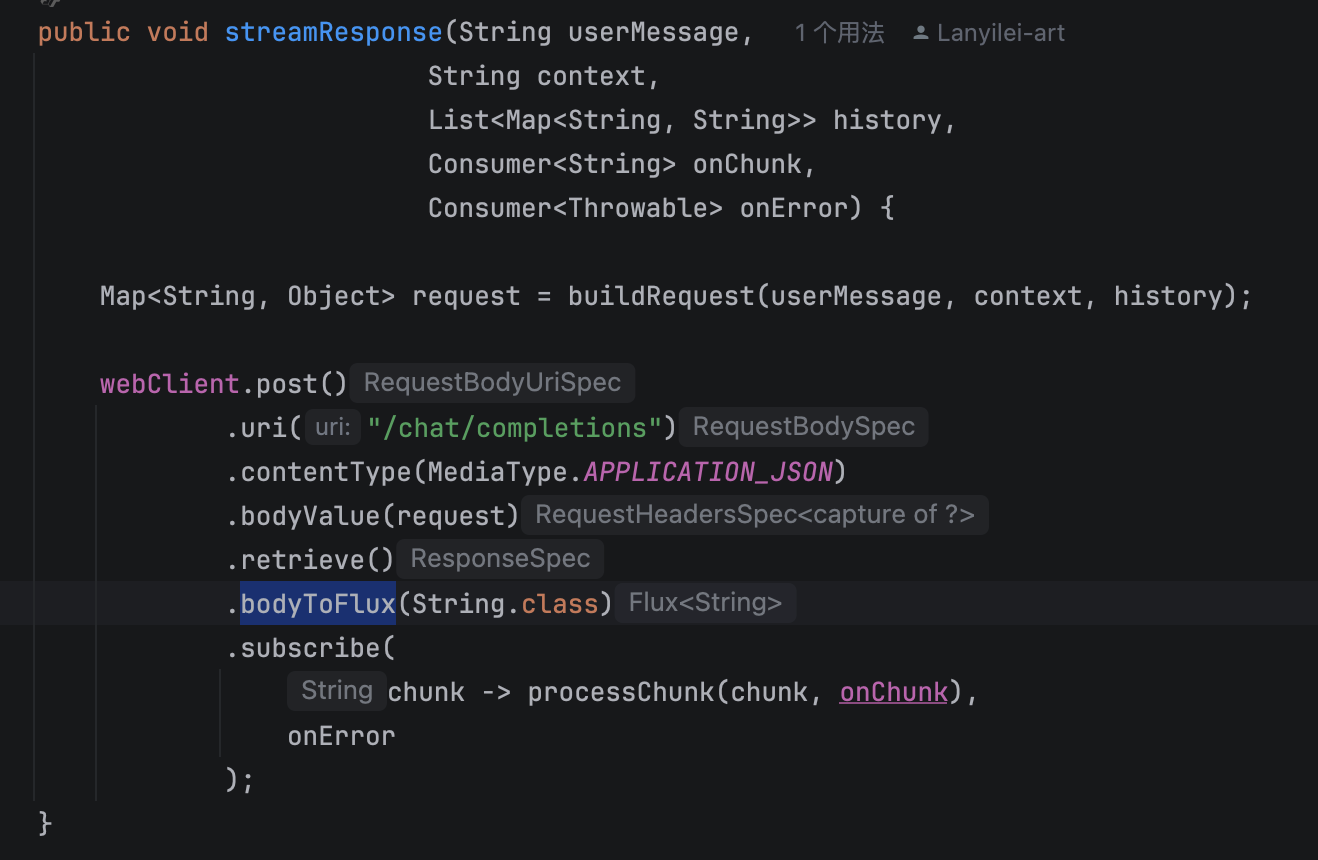
每接收一段内容,就通过 WebSocket 立刻推送给前端。前端收到一小段字符后,就直接追加到聊天窗口中,给用户的感觉就是“打字机一点一点显示”的效果。
2.既然用到了WebSocket,那它和我们更常用的HTTP请求相比,有什么本质区别?为什么在这个场景下,必须用WebSocket?
WebSocket 能够支持服务端主动、实时地向客户端推送数据,而 HTTP 不具备这个能力。

具体来说,HTTP 是一种无状态、单向的请求-响应协议,它的工作机制决定了只能由客户端发起请求,服务端只是被动响应。哪怕我们用长...
已加入星球,可直接知识星球授权登录
二哥编程星球目前包含:
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

44人已点赞
热门评论
89 条评论
回复