


用 SQLite + Embedding 给 Agent 加上 RAG,从此秒懂项目源码
大家好,我是二哥呀。
这一期我们来给 Agent 装上 RAG,让 Agent 可以直接读我们的代码库。
举个具体场景,我问“MemoryManager 是怎么压缩上下文的”。没有 RAG 的 Agent 只能凭训练数据瞎猜,猜得对算运气好。
装了 RAG 之后,Agent 会先去代码库里捞 ContextCompressor.compressIfNeeded,看 Map-Reduce 的实现,再基于这段真实代码的回答。
整个 RAG 的架构示意图如下所示。
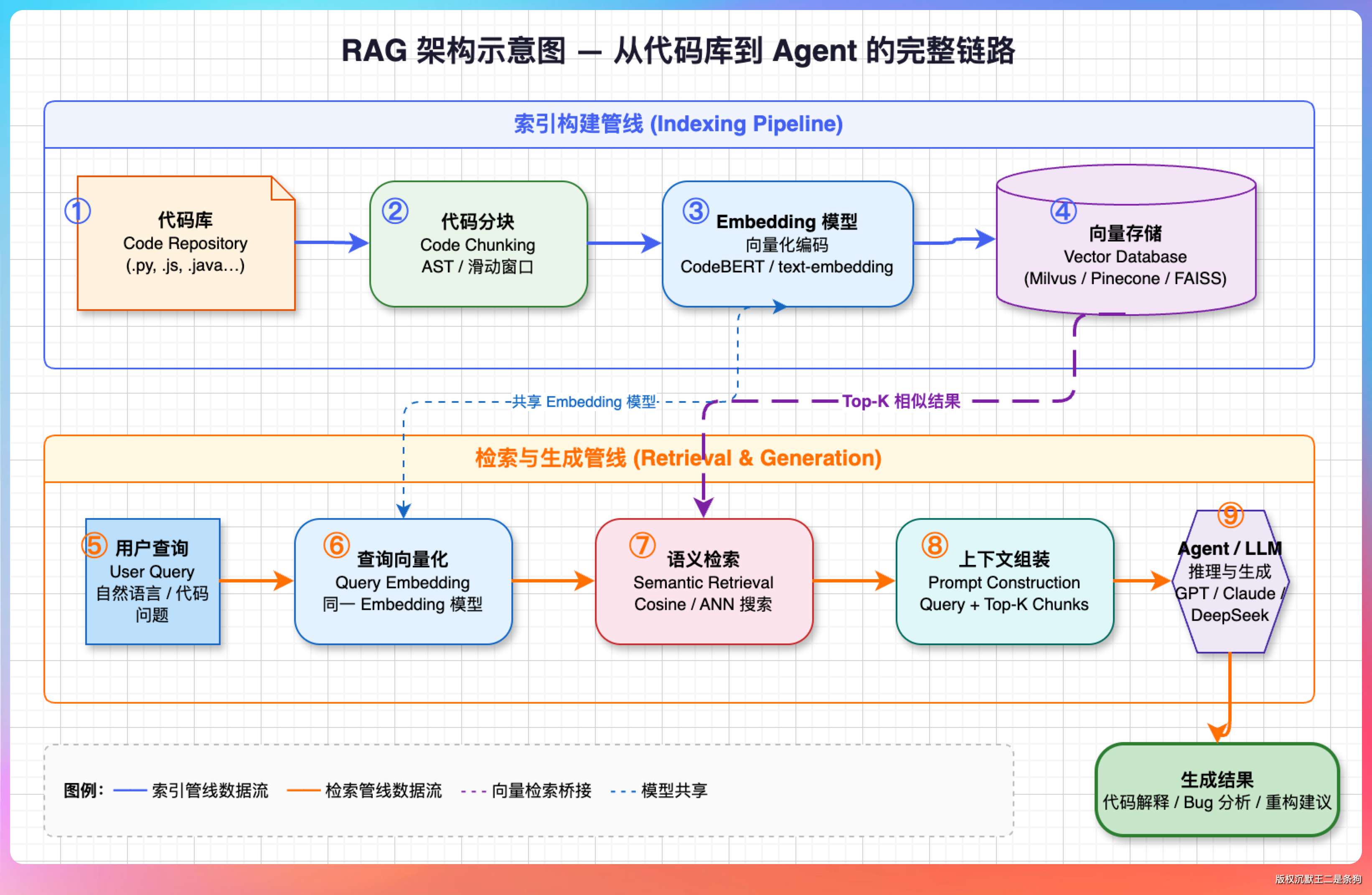
01、RAG 的整体设计
RAG 大家应该不陌生了,一句话讲清楚。
把知识库向量化然后持久化到向量数据库,查询的时候,按照语义相似度找出最相关的片段,再连同问题一起塞给 LLM。
落到代码场景,有三个问题绕不开。
第一个是怎么切。代码不像文档,按字数硬切会切出了很多噪音。最稳妥的办法是按结构特征切——文件级、类级、方法级,检索时按粒度匹配。
第二个是存到哪。生产环境通常上 Milvus、Pinecone 、ElasticSearch 这种专用向量库。但我们是个 CLI 工具,这些都太重量级了。
所以我这里选择了 SQLite。
第三个是怎么样才能搜得准。纯向量检索对自然语言友好,对代码标识符却不一定。
所以我们这里做了混合检索——语义打底、关键词加权、再按 chunk 类型加分。method 块比 file 块优先级高,因为用户问“怎么实现的”,给方法体比给整个文件有用得多。
举个例子,搜“处理用户登录的地方”,它能定位到 LoginService.authenticate。
整个 RAG 模块拆成 10 个类,下面一块一块讲。
CodeChunk —— 代码块数据模型
CodeChunker —— AST 分块
EmbeddingClient —— 向量化客户端
VectorStore —— SQLite 向量存储
CodeAnalyzer —— AST 关系分析
CodeRelation —— 关系数据模型
CodeIndex —— 索引入口
CodeRetriever —— 检索入口
RagQueryTokenizer —— 查询分词
SearchResultFormatter —— 结果格式化
02、AST 解析
代码分块是 RAG 里最容易被低估的一步。分得好,检索准;分得糙,后面再多加权也救不回来。
Java 文件和非 Java 文件得分开处理。
Java 走 AST,按类和方法切;非 Java(比如 Markdown、yaml)就按字符大小切,每段控制在 2000 字符以内。
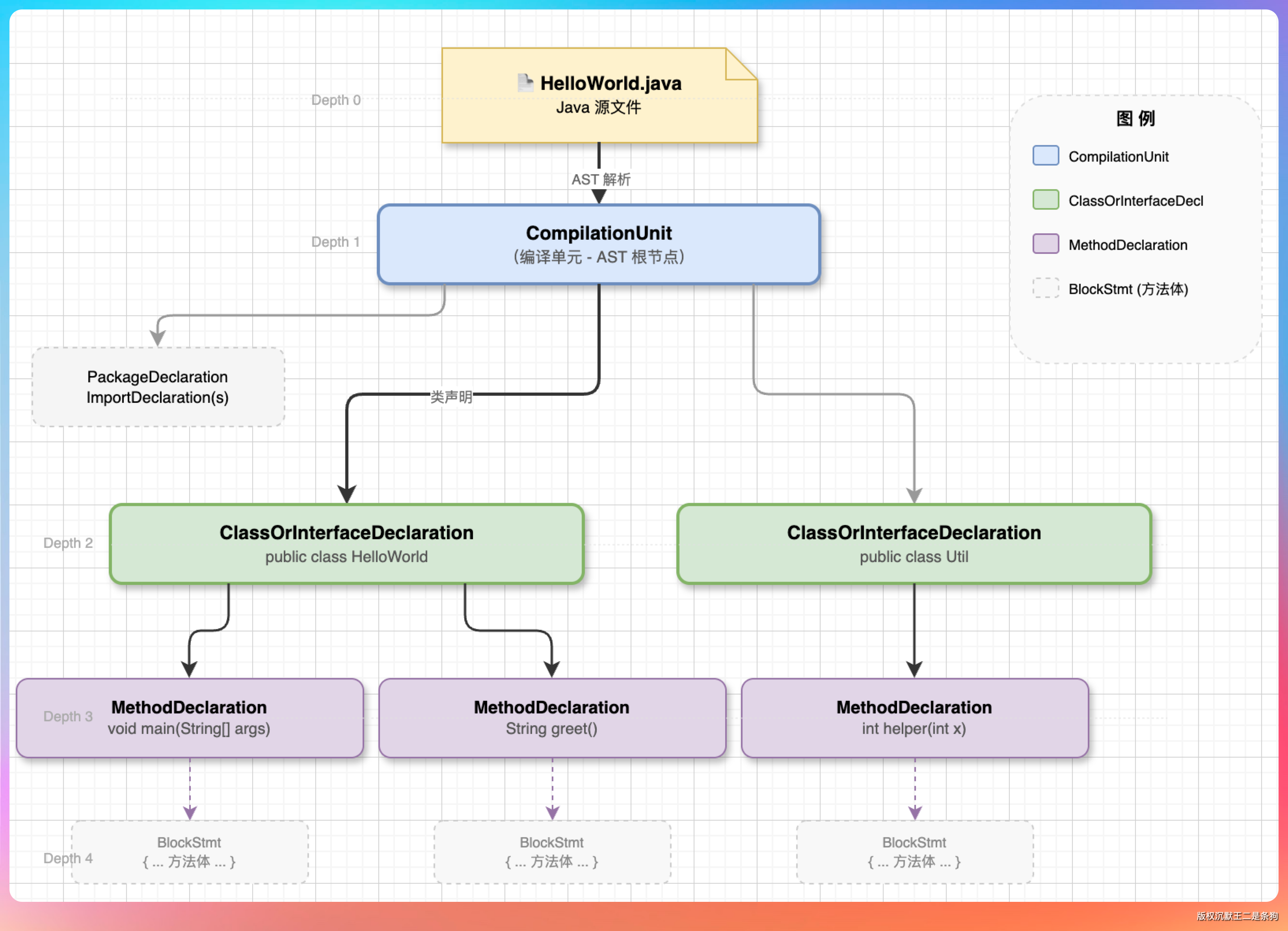
Java 这块用 JavaParser,CodeChunker 里的核心逻辑是这样:
public List chunkFile(Path filePath) throws IOException {
String content = Files.readString(filePath);
// 非 Java 文件:按大小分段
if (!relativePath.endsWith(".java")) {
return chunkLargeText(relativePath, content);
}
// Java 文件:AST 解析分块
return chunkJavaFile(filePath, content);
}
JavaParser 可以把语言级别设到 JAVA_17,text block、record、sealed class 这些新语法都能正常解析。
万一遇到语法错误,可以自动回退到按大小分段,不会因为一个文件解析失败就漏掉整块代码。
非 Java 文件超过 2000 字符就生成一个 chunk,同时把起止行号一起带上。检索结果直接能跳到对应行,不用二次定位。
Java 这边类级和方法级各存一份。
类级只保留类声明和前 5 行(字段、签名这些信息够用了),不用把几百行的类全塞进去;方法级则把完整方法体捞出来,单独成块。
// 类级别 chunk
chunks.add(CodeChunk.classChunk(
filePath.toString(), className,
classHeader, classStart, classEnd));
// 方法级别 chunk
chunks.add(CodeChunk.methodChunk(
filePath.toString(),
className + "." + methodSignature,
methodContent, methodStart, methodEnd));
CodeChunk 用的是 record,除了正文内容,还带了文件路径、块类型、名称、起止行号。
toEmbeddingText 方法会把这些拼成 [method:Agent.run] public String run(...) 这种格式再去算向量,让模型一眼看清这是哪个类的哪个方法。
CodeIndex 是整个索引流程的入口,把“遍历文件 → 分块 → 向量化 → 持久化”封装进去。
外面只要一行 codeIndex.index("/path/to/project") 就能跑起来。
遍历用的是 Files.walkFileTree,node_modules、target、.git、build 这些目录直接跳...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

6人已点赞
热门评论
43 条评论
回复