


AI Agent 面试题第一弹:ReAct、Plan-and-Execute、Multi-Agent 核心架构 13 题
第一弹,聚焦 Agent 核心架构——ReAct、Plan-and-Execute、Multi-Agent、异步并行。
这几个方向面试出现的频率最高,也是 PaiCLI 第 1、2、5、7 期的核心内容。
01、什么是 ReAct 模式?
ReAct 是 Reasoning + Acting 的缩写,Yao et al.(姚顺雨)在 2022 年提出。
核心就一句话:让 LLM 在推理的同时能执行动作,根据动作结果继续推理,形成一个闭合的循环。
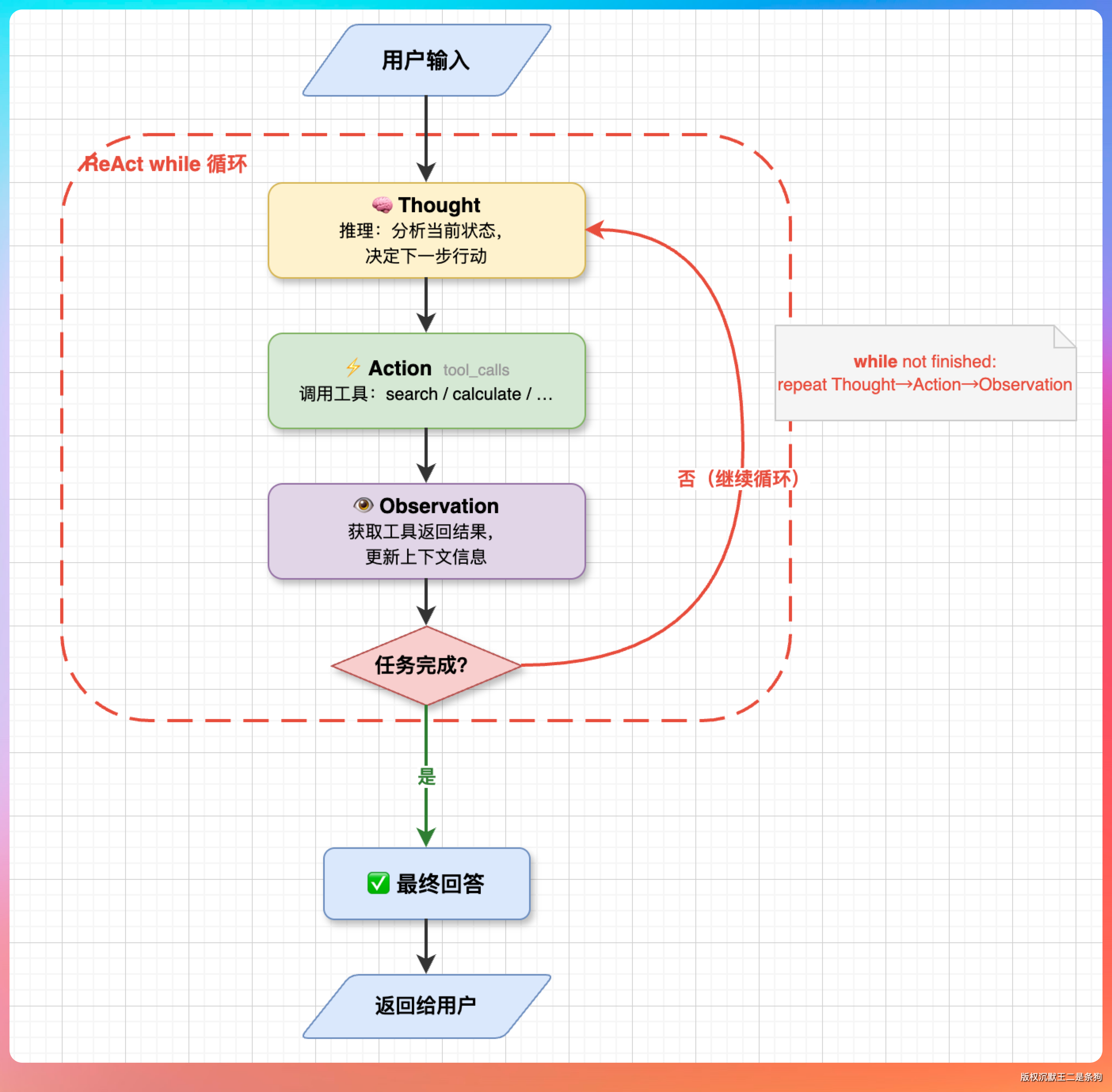
PaiCLI 第一期的 Agent.java 就是一个标准的 ReAct 实现。核心是一个 while 循环,每轮做三件事:
- 把消息历史发给 LLM、
- 检查响应里有没有
tool_calls - 有的话执行工具把结果塞回历史。
LLM 不再返回 tool_calls 就退出循环,把最终回复输出给用户。
整个 Agent 的骨架就这么简单。
它和 Chain-of-Thought 有什么区别?
Chain-of-Thought(CoT)只推理不执行。
LLM 一口气想完所有步骤,直接输出最终答案。做数学题、逻辑推理可以,但碰到“帮我读一下 pom.xml”这种需要外部信息的任务就歇菜了——LLM 没有读文件的能力,想得再好也是瞎猜。
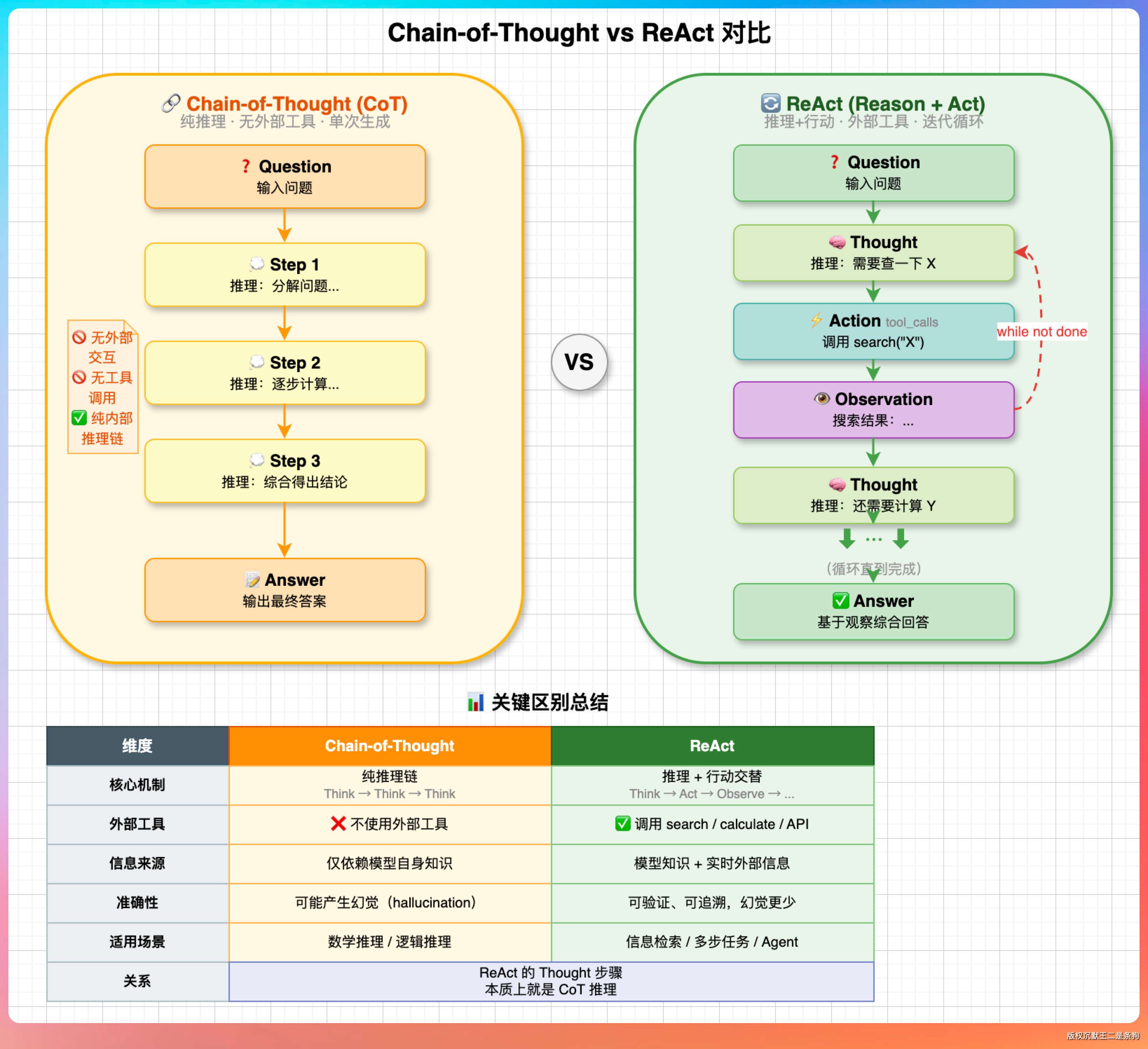
ReAct 的突破在于加了 Action 和 Observation 两个环节。LLM 想到“我需要读 pom.xml”,就输出一个 read_file 的 tool_call,Agent 真去读了文件,把内容返回回来,LLM 基于真实的内容继续推理。
用一个表格说清楚两者的边界:
| 维度 | CoT | ReAct |
|---|---|---|
| 能力范围 | 纯推理 | 推理 + 外部工具调用 |
| 信息来源 | 训练数据里的知识 | 实时获取(文件、命令、搜索) |
| 适合场景 | 数学、逻辑、代码生成 | 需要与外部世界交互的任务 |
| 典型产品 | ChatGPT 的思考过程 | Claude Code、PaiCLI、Cursor |
面试官追问到这一步,可以补一句:
PaiCLI 的 LLM 响应里也有 reasoning_content(思考过程),这个其实就是 CoT 的部分。
ReAct 不是替代 CoT,而是在 CoT 的基础上加了行动能力。PaiCLI 的源码里,reasoning_content 只写日志不进下一轮对话历史,避免思考过程占用 Token 预算。
02、Agent 怎么知道该调用哪个工具?
这道题很多人会答错,以为 Agent 里有个什么路由规则在做工具匹配。实际上 Agent 本身不做工具选择,选择权完全在 LLM 手里。
流程是这样的:Agent 在构造请求时,把所有可用工具的定义(名称 + 描述 + 参数 JSON Schema)放在请求体的 tools 字段里发给 LLM。LLM 根据用户意图和工具描述,在响应的 tool_calls 字段里返回工具名和参数 JSON。
这就是 OpenAI 定义的 Function Calling 协议,GLM、DeepSeek、Kimi 这些国产模型也都兼容。
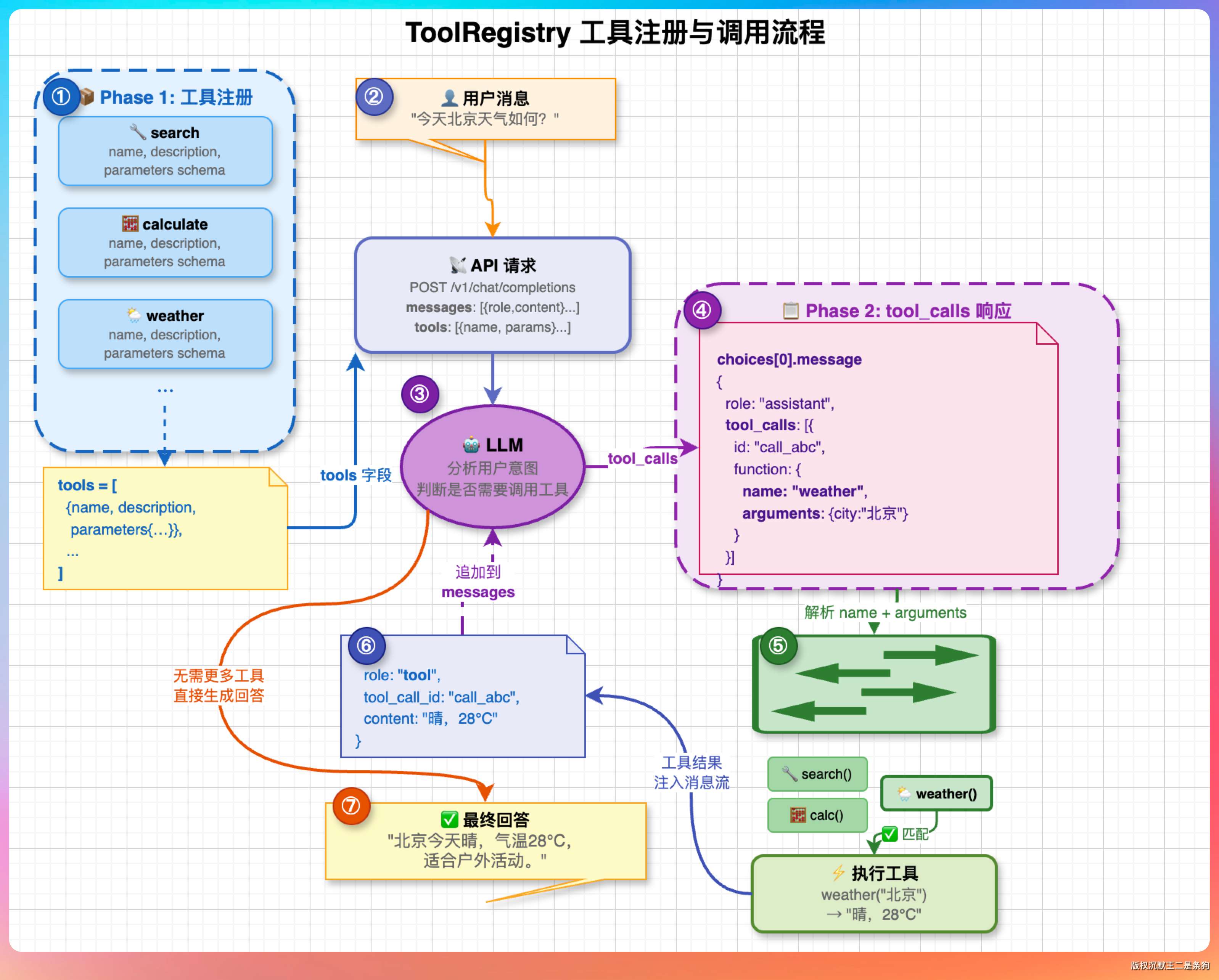
PaiCLI 的 ToolRegistry.java 维护了一个工具注册表。每个工具注册时提供 name、description、parameters schema。Agent 每次请求 LLM 前,从注册表拉出全量工具定义塞进请求体。LLM 返回 tool_calls: [{name: "read_file", arguments: {path: "pom.xml"}}],Agent 就从注册表里找到 read_file 的执行逻辑来跑。
// ToolRegistry.java 核心结构
private final Map tools = new LinkedHashMap<>();
private final Map executors = new LinkedHashMap<>();
public String executeTool(String name, String argumentsJson) {
ToolExecutor executor = executors.get(name);
if (executor == null) {
return "未知工具: " + name;
}
return executor.execute(argumentsJson);
}
这里有个实战经验值得提一下:工具描述的质量直接决定 LLM 的选择准确率。
PaiCLI 早期 execute_command 的描述写得太简洁,LLM 经常用...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

20人已点赞
热门评论
27 条评论
回复