


010.正则式匹配——二哥的 LeetCode 刷题笔记 Java 版
题意
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
- '.' 匹配任意单个字符
- '*' 匹配零个或多个前面的那一个字符
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例
输入:s = "aa", p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
输入:s = "aa", p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 前面的字符是 'a',因此,字符串 "aa" 可被视为 'a' 重复了一次。
输入:s = "ab", p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
提示
- 1 <= s.length <= 20
- 1 <= p.length <= 20
- s 只包含从 a-z 的小写字母。
- p 只包含从 a-z 的小写字母,以及字符 . 和 *。
- 保证每次出现字符 * 时,前面都匹配到有效的字符
难度
难
分析 1
正则表达式其实是一个非常宏大的知识体系,在日常开发中其实也蛮常用,尤其是做一些数据校验的时候,比如说手机号码、邮箱、身份证号码等等,都可以通过正则表达式来进行校验。
还有一些处理复杂字符串的时候,比如说我要通过一定的规则从一个庞大的字符序列中找出想要的内容,比如说从 HTML 页面的源码中找出标题、作者、正文等,那由于 HTML 页面的结构比较复杂,我们就需要通过正则表达式来进行匹配查找。
如果之前没有了解过正则表达式的话,可以先通过 B站上这个视频进行了解:
如果觉得 10 分钟的视频还是太长,想要文档,那么推荐大家看看 GitHub 上这个仓库:
大致了解正则表达式是什么,有什么作用后,对这道题会有更清晰的解题思路。
一句话总结下:正则表达式就是一种用来匹配字符串的规则。
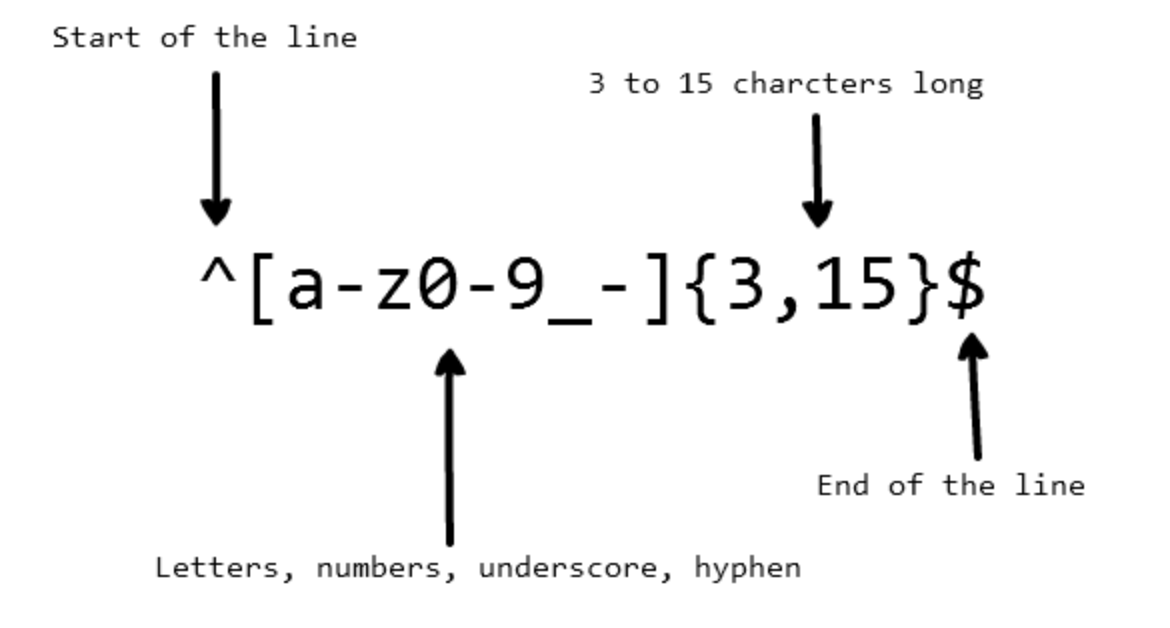
上面是一个比较简单的正则表达式,具体解释如下:
^:匹配输入字符串的开始位置。[a-zA-Z0-9_-]:字符集合。匹配所有小写字母 (a-z)、大写字母 (A-Z)、数字 (0-9),以及下划线 (_) 和中划线 (-)。{3,15}:表示匹配 3-15 个前面的字符。$:匹配输入字符串的结束位置。
所以这个正则表达式的意思就是:匹配一个长度为 3-15 个字符的字符串,且只能包含小写字母、大写字母、数字、下划线和中划线。
回到本题,s 只包含从 a-z 的小写字母;p 只包含从 a-z 的小写字母,以及字符 . 和 *。
如果只有.的话,事情就很简单,因为 . 可以匹配任意单个字符,所以我们只需要遍历 s 和 p,然后逐个字符进行匹配即可。
但是这里还有一个*,*就比较麻烦了,因为它可以匹配零个或多个前面的那一个字符。
所以我们需要考虑的情况就变得多了,比如说:
s = "aa", p = "a*":这种情况下,*可以匹配零个或多个前面的那一个字符,所以a*可以匹配""、"a"、"aa",所以这种情况下是可以匹配的。s = "ab", p = ".*":这种情况下,.*可以匹配零个或多个前面的任意字符,所以.*可以匹配""、"a"、"ab"、"abb"、"abbb"、"abbbb",所以这种情况下是可以匹配的。
所以我们需要*的前一个字符到底能够匹配多少个字符。我打算先采用递归的方式来处理,这样的思路会比较简单、直接、暴力。
递归方法的核心在于将问题分解成更小的子问题。对于每一个字符,我们需要判断它是否与模式中的字符匹配,然后递归地处理剩余的字符串。
①、基本情况:如果模式字符串...
企业级Agent工作流编排项目PaiFlow
Vibe Coding版本的PaiAgent
派聪明RAG AI知识库Java版本+Go版本
微服务 PmHub、技术派、MYDB
求职派JobClaw(OpenClaw/Hermes架构
PaiCLI(类似Claude Code的Agent
派简历(代码已完成)
等实战项目。
1. 微信扫右侧的优惠券加入知识星球
2. 解锁星球的实战项目教程和源码: 项目源码+教程获取

1人已点赞
热门评论
4 条评论
回复